



Human features as objects of study have been widely used in various machine learning applications — be it face detection, video surveillance or even the development of autonomous cars. In fact, the task of ascertaining human features becomes the major work of ML systems in these applications. However, in the case of video surveillance, capturing human figures at an aerial level, especially from a moving equipment, becomes very challenging. Due to factors such as video equipment alignment or lighting, the accuracy of detection in the system takes a hit significantly.
In order to resolve these issues, researchers are now exploring deep learning (DL) in video surveillance. Earlier studies usually relied on computer vision concepts such as local binary pattern (LBP) or feature transforms to extract features from images and later trained with classification algorithms.
Subsequent studies used convolutional neural networks (CNN) to handle large image datasets. For example, the popular CNN model AlexNet has classified more than one million images. In this article, we will discuss the latest study on human detection in aerial videos which has used three different DL models.
A Real-Time Approach
Nouar AlDahoul, Aznul Qalid Md Sabri, and Ali Mohammed Mansoor, researchers from the University of Malaya, Kuala Lumpur, bring out a research study which explores DL for real-time human detection from aerial videos. They use three DL models:
- Supervised CNN model
- Pretrained CNN model
- Hierarchical extreme learning machine (HELM) model
All of these models are trained and tested for the UCF-ARG aerial dataset. This dataset consists of images in the form of video frames which capture a set of human actions aerially. Actions include running, walking, throwing among others captured on a moving camera.
In the first stage, the researchers build an optical flow model for all the three DL models so that inputs from the training and testing samples hold good for human detection as well as to achieve image stabilisation. For this purpose, video frames in the dataset are fed as input for this optical flow model.
“Optical flow estimates the speed and direction of the motion vector between sequences of frames. This stage is important because it tackles the camera movement issue that results from the moving aerial platform. Feature images are produced by thresh-holding and performing a morphological operation (closing) to the motion vectors. Blob analysis is then performed to locate moving objects in each binary feature image. Next, green boundary boxes are overlaid surrounding the detected objects. The quality of optical flow for background stabilization is important as it is the first stage before feature learning is performed via deep models which act as input for the classifiers.”
Once the optical flow model is set to stabilise the human actions, DL models are created for human detection.
Deep Model Implementations
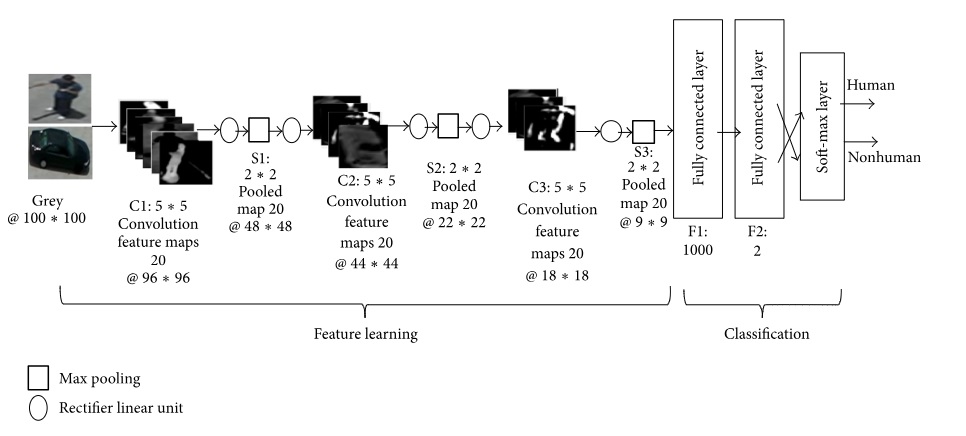
Supervised CNN model: In this model, a supervised CNN is used for human detection. The CNN architecture has 17 network layers which includes one input layer, three convolutional layers, three max-pooling layers, six rectifier linear unit layers, and two fully connected layers with a soft-max layer. Features are now extracted in the eighth layer.
Stochastic gradient descent (SGD) is the method used for training the model network. In addition to that, the soft-max layer segregates human and non-human objects in training. The CNN layers and the network architecture are presented as follows:
- Image input layer with 100 * 100 pixels grey image.
- Convolution layer: 20 feature maps of 5 * 5.
- Relu layer
- Max-pooling layer: pooling regions of size [2,2] and returning the maximum of the four.
- Relu layer.
- Convolution layer: 20 feature maps of 5 * 5
- Relu layer.
- Max-pooling layer: pooling regions of size [2,2] and returning the maximum of the four.
- Relu layer.
- Convolution layer: 20 feature maps of 5 * 5.
- Relu layer
- Max-pooling layer: pooling regions of size [2,2] and returning the maximum of the four.
- Fully connected layer: with 1,000 nodes.
- Relu layer.
- Fully connected layer with 2 classes.
- Soft-max layer.
- Classification layer.
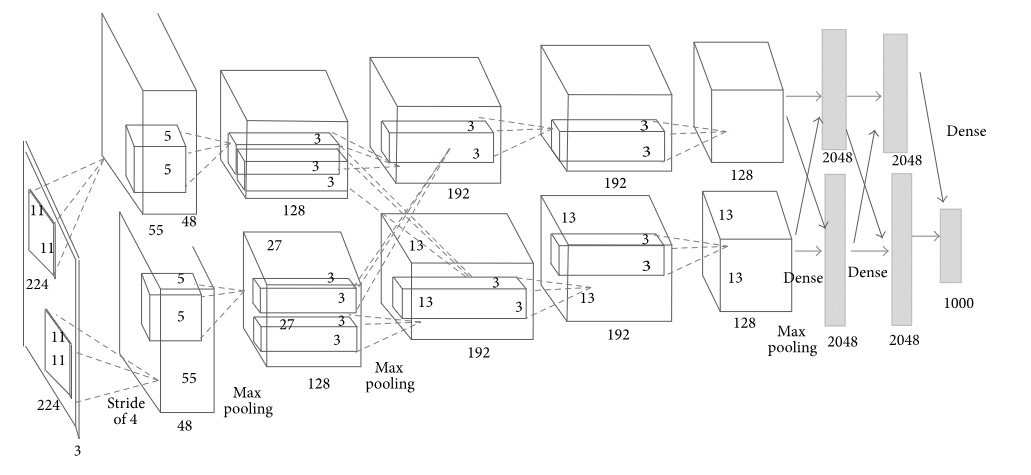
Pre-trained CNN model: This DL model considers the AlexNet architecture for detection. The networks include five convolutional layers, ReLU layers, max-pooling layers, three fully-connected layers, a soft-max layer, and a classification layer. An important consideration here is that the input RGB images are resampled to 2272273 pixels. Feature extraction is at the seventh layer by an activation function.
Just like the previous model, SGD is used to train the model along with an SVM classifier to classify features into human and nonhuman classes. The network architecture is given below:
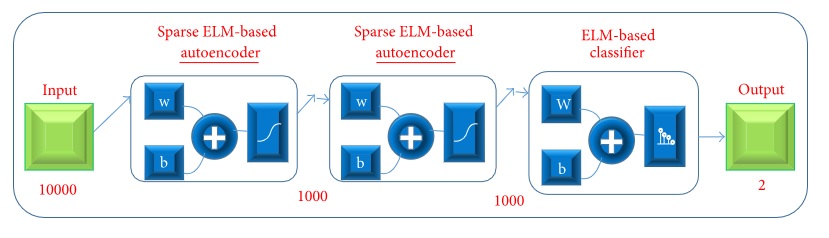
Hierarchical Extreme Learning Machine(HELM) model: This model entails autoencoders which are based on the concepts of extreme learning machines. The architecture consists of three modules including two sparse ELM-based autoencoders, and an ELM-based classifier. Unlike the previous models, grey images are used as inputs in this model. Distinguishing human and non-human classes are done by the ELM-based classifier in the last module. The HELM model is given below:
Performance Of The Models
All the three models are trained and tested extensively for the dataset. When it comes to performance, they offer a very high accuracy in human detection (close to 99 percent) along with speed (training times being 10 minutes and testing times as fast as 0.1 seconds). For implementation, NVIDIA GeForce GTX 950 was the GPU used in this study. Comparably, the HELM model fares better than the other two models. A detailed analysis can be found here.
Conclusion
With this study, detecting human figures has been made easier in an environment bound with non-human objects in addition to varying motions of these objects. The striking feature of this study is that all of the processes are happening in a real-time scenario. This will definitely be a big boost for critical areas such as video surveillance.















































































