






Over the last few decades machines have become much smarter but without a properly labelled training data set of seen classes, it cannot distinguish between two similar objects. On the other hand, humans are capable of identifying approximately 30,000 basic object categories. In machine learning, this is considered as the problem of zero-shot learning (ZSL). Let us consider an example, a child would have no problem recognising a zebra if it has seen a horse before and read somewhere that a zebra looks similar to a horse, but has black-and-white stripes.
In case of machines, the ZSL recognition relies on the existence of a labelled training set of seen classes and the knowledge about how each unseen class is semantically related to the seen classes.
According to a research paper, the reason why humans can perform ZSL is because of their existing language knowledge base, which provides a high-level description of a new or unseen class (zebra) and makes a connection between it and seen classes and visual concepts (horse, stripes). Inspired by this humans ability, there is an increasing interest in machine ZSL for scaling up visual recognition.
Zero-Shot Learning 101
A study explains that zero-shot machine learning is used to construct recognition models for unseen target classes that have not labelled for training. It utilises the class attributes as aside information and transfers information from source classes with labelled samples. ZSL is done in two stages:
- Training: Where the knowledge about the attributes is captured
- Inference: The knowledge is then used to categories instances among a new set of classes.
Recently, there has been a surge in interest in automatic recognition of attributes, due to the availability of data containing meta information. A research paper claims that this has proved to be particularly useful for recognising images.
Zero-shot learning approaches are designed to learn intermediate semantic layer, their attributes, and apply them at inference time to predict a new class of data, claims a study.
Li Zangs’ study further explains, zero-shot learning also relies on the existence of a labelled training set of seen classes and unseen class. Both seen and unseen classes are related in a high dimensional vector space, called semantic space, where the knowledge from seen classes can be transferred to unseen classes.
With the semantic space and a visual feature representation of image content, Li Zang and a group of researchers solved ZSL in two steps:
- A joint embedding space is learned where both the semantic vectors (prototypes) and the visual feature vectors can be projected to.
- Nearest neighbour (NN) search is performed in this embedding space to match the projection of an image feature vector against that of an unseen class prototype.
Implementing Zero-Shot Learning
In order to make ZSL effective, the key features (images and text) are categorised as vectors. This means sourcing the specific vectors beforehand for the project. Once collected, they are provided with a description which enables the algorithms to classify them accordingly. The training is done with respect to these vectors which leads to classification according to separate classes. The testing phase recognises new inputs and again leads to newer classes, regardless of the train data.
Steps Involved In Implementation:
In a tutorial, Timothy Hospedales described three steps to implement zero-shot learning in a model:
- Obtain category vector, V, through:
- Attributes: It describes the visual appearance of the concept or instance by assigning labelled visual properties to it and they can be easily transferred from seen to unseen classes.
- Word vectors: It is a straightforward application to other data types such as video, text and audio, among others.
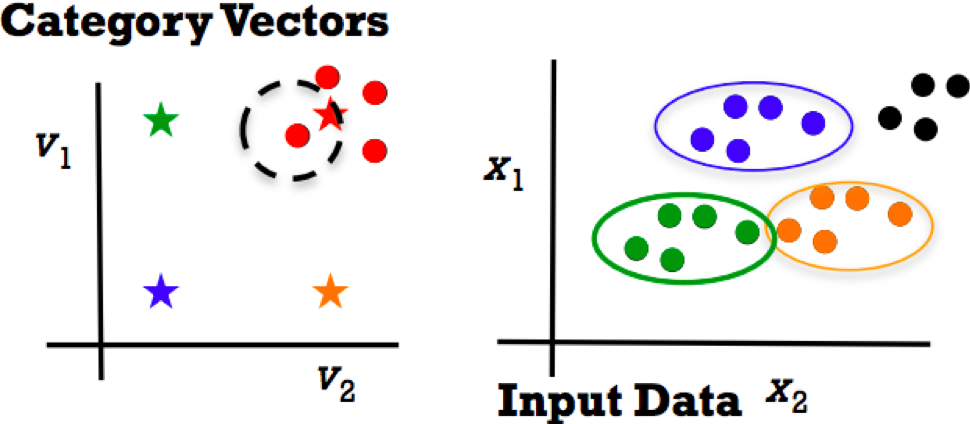
- Train:
- Give some know class category vectors V and images X
- Learn images by categorising them as vector classifiers or regressors V=F(X)
- Test:
- Specify vector V for a new class to recognise
- Map test data F(X) to category vector space
- NN matching of V vs F(X)
Deep Zero-shot learning
In older times, ZSL works used hand-crafted feature representations for objects. They have been replaced by features extracted from deep convolutional neural networks (CNN) in the past two years for visual feature representation. Here, the features are extracted with pre-trained CNN models. The deep CNNs are also used as inputs to their embedding model. Existing DNN-based ZSL works differ on whether they use the semantic space or an intermediate space as the embedding space.
How To Train An End-To-End ZSL In Deep Models
- Train E (X,Z) to be large for machine pairing, small for mismatched pairs.
- Let E (X,Z) be a deep network rather than bilinear model
- Concatenate (X,Z) and feed into a deep network
- It is better to do some representation learning on X and Z, then the inner product.
A Simple Deep Network For ZSL As Explained In Timothy’s Tutorial
Train a max-margin ranker. Or Y=(1,0) for (matching, mismatching pair) pairs.

According to a study, despite the success of deep neural networks which learn an end-to-end model between text and images in other vision problems such as image captioning, very few deep ZSL models exist. The deep ZSL models show little advantage over ZSL models which utilise deep feature representation but do not learn an end-to-end embedding.


















