Feature selection is the method of reducing data dimension while doing predictive analysis. One major reason is that machine learning follows the rule of “garbage in-garbage out” and that is why one needs to be very concerned about the data that is being fed to the model.
In this article, we will discuss various kinds of feature selection techniques in machine learning and why they play an important role in machine learning tasks.
Filter Method
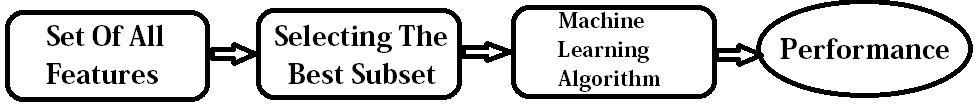
This method uses the variable ranking technique in order to select the variables for ordering and here, the selection of features is independent of the classifiers used. By ranking, it means how much useful and important each feature is expected to be for classification. It basically selects the subsets of variables as a pre-processing step independently of the chosen predictor. In filtering, the ranking method can be applied before classification for filtering the less relevant features. It carries out the feature selection task as a pre-processing step which contains no induction algorithm.
Some examples of filter methods are mentioned below:
- Chi-Square Test: In general term, this method is used to test the independence of two events. If a dataset is given for two events, we can get the observed count and the expected count and this test measures how much both the counts are derivate from each other.
- Variance Threshold: This approach of feature selection removes all features whose variance does not meet some threshold. Generally, it removes all the zero-variance features which means all the features that have the same value in all samples.
- Information Gain: Information gain or IG measures how much information a feature gives about the class. Thus, we can determine which attribute in a given set of training feature is the most meaningful for discriminating between the classes to be learned.
Wrapper Method

Fig: Wrapper Approach to feature subset selection
The Wrapper Methodology was made famous by researchers Ron Kohavi and George H. John in the year 1997. This method utilises the learning machine of interest as a black box to score subsets of variables according to their predictive power. In the above figure, in a supervised machine learning, the induction algorithm is depicted with a set of training instances, where each instance is described by a vector of feature values and a class label. The induction algorithm which is also considered as the black box is used to induce a classifier which is useful in classifying. In the wrapper approach, the feature subset selection algorithm exists as a wrapper around the induction algorithm. One of the main drawbacks of this technique is the mass of computations required to obtain the feature subset.
Some examples of Wrapper Methods are mentioned below:
- Genetic Algorithms: This algorithm can be used to find a subset of features. CHCGA is the modified version of this algorithm which converges faster and renders a more effective search by maintaining the diversity and evade the stagnation of the population.
- Recursive Feature Elimination: RFE is a feature selection method which fits a model and removes the weakest feature until the specified number of features is satisfied. Here, the features are ranked by the model’s coefficient or feature importances attributes.
- Sequential Feature Selection: This naive algorithm starts with a null set and then add one feature to the first step which depicts the highest value for the objective function and from the second step onwards the remaining features are added individually to the current subset and thus the new subset is evaluated. This process is repeated until the required number of features are added.
Embedded Method
This method tries to combine the efficiency of both the previous methods and performs the selection of variables in the process of training and is usually specific to given learning machines. This method basically learns which feature provides the utmost to the accuracy of the model.
Some examples of Embedded Methods are mentioned below:
- L1 Regularisation Technique such as LASSO: Least Absolute Shrinkage and Selection Operator (LASSO) is a linear model which estimates sparse coefficients and is useful in some contexts due to its tendency to prefer solutions with fewer parameter values.
- Ridge Regression (L2 Regularisation): The L2 Regularisation is also known as Ridge Regression or Tikhonov Regularisation which solves a regression model where the loss function is the linear least squares function and regularisation.
- Elastic Net: This linear regression model is trained with L1 and L2 as regulariser which allows for learning a sparse model where few of the weights are non-zero like Lasso and on the other hand maintaining the regularisation properties of Ridge.
Importance
The feature selection techniques simplify the machine learning models in order to make it easier to interpret by the researchers. IT mainly eliminates the effects of the curse of dimensionality. Besides, this technique reduces the problem of overfitting by enhancing the generalisation in the model. Thus it helps in better understanding of data, improves prediction performance, reducing the computational time as well as space which is required to run the algorithm.