



These action potentials can be thought of as activation functions in the case of neural networks. The path that needs to be fired depends on the activation functions in the preceding layers just like any physical movement depends on the action potential at the neuron level.

Deep neural networks are trained, by updating and adjusting neurons weights and biases, utilising the supervised learning back-propagation algorithm in conjunction with optimization technique such as stochastic gradient descent.

Each artificial neuron receives one or more input signals x 1, x 2,…, x m and outputs a value y to neurons of the next layer. The output y is a nonlinear weighted sum of input signals. A Neural Network without Activation function would simply be a Linear regression Model. Non-linearity is achieved by passing the linear sum through non-linear functions known as activation functions.
The Activation Functions can be basically divided into 2 types-
- Linear Activation Function
- Non-linear Activation Functions
ReLU, Sigmoid, Tanh are 3 the popular activation functions(non-linear) used in deep learning architectures.
How Good Are Sigmoid And Tanh
The problems with using Sigmoid is their vanishing and exploding gradients. When neuron activations saturate closer to either 0 or 1, the value of the gradients at this point come close to zero and when these values are to be multiplied during backpropagation say for example, in a recurrent neural network, they give no output or zero signal. Added to this problem, is that the sigmoid output is not zero-centred. That means if the value of the function is positive, it makes gradients of the weights all positive or all negative, making the gradients reaching for extremities in either direction, that is, exploding gradients. So, sigmoids are usually preferred to run on the last layers of the network.
To avoid the problems faced with a sigmoid function, a hyperbolic tangent function(Tanh) is used.
Tanh function gives out results between -1 and 1 instead of 0 and 1, making it zero centred and improves ease of optimisation. But, the vanishing gradient problem persists even in the case of Tanh.
Why ReLU
Rectified Linear Unit or ReLU is now one of the most widely used activation functions. The function operates on max(0,x), which means that anything less than zero will be returned as 0 and linear with the slope of 1 when the values is greater than 0. And, ReLU boasts of having convergence rates 6 times to that of Tanh function when it was applied for ImageNet classification.
The learning rate with ReLU is faster and it avoids the vanishing gradient problem. But, ReLU is used for the hidden layers. Whereas, a softmax function is used for the output layer during classification problems and a linear function during regression.
The drawback with ReLU function is their fragility, that is, when a large gradient is made to flow through ReLU neuron, it can render the neuron useless and make it unable to fire on any other datapoint again for the rest of the process. In order to address this problem, leaky ReLU was introduced.
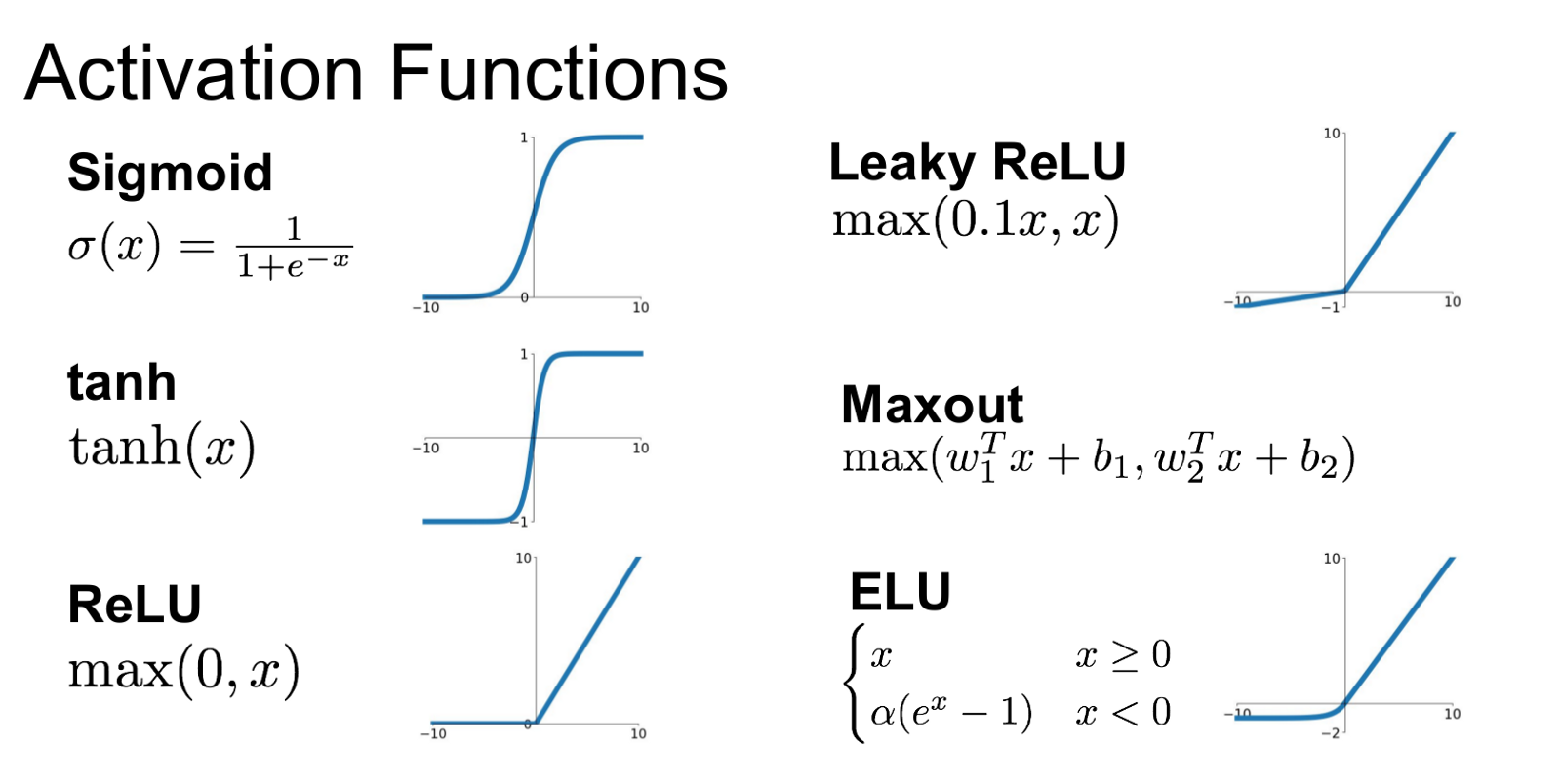
So, unlike in ReLU when anything less than zero is returned as zero, leaky version instead has a small negative slope. One more variant to this can be the Maxout of function which is a generalisation of both ReLU and its leaky colleague.
Based on the popularity in usage and their efficacy in functioning at the hidden layers, ReLU makes for the best choice in most of the cases.


































































































