



Transmitting sound through a machine and expecting an answer is a human depiction is considered as an highly-accurate deep learning task. Every one of us has come across smartphones with mobile assistants such as Siri, Alexa or Google Assistant. These are dominating and in a way invading human interactions.
The neural networks built with memory capabilities have made speech recognition 99 percent accurate. Neural networks like LSTMs have taken over the field of Natural Language Processing. A person’s speech can also be understood and processed into text by storing the last word of the particular sentence which is fascinating. To understand how these state-of-the-art applications work, lets us break down the whole process of sound recognition to machine translation.
Wave Breakdown
The audio signal is separated into different segments before being fed into the network. This can be performed with the help of various techniques such as Fourier analysis or Mel Frequency, among others. The graph below is a representation of a sound wave in a three-dimensional space. A Fourier transform can be performed on a sound wave to represent and visualise them in time or frequency domain.

Source: www.tes.com
Let us consider a stereo .wav file which consists of two words, “nice work”. This file is about one second long and is a dual audio channel wave. Breaking this down into separate channels will help us visualise the wave.
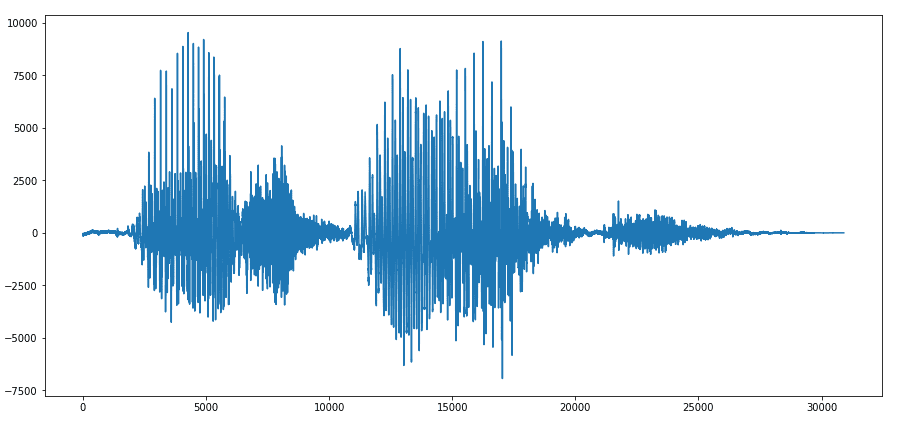
This graph represents one channel and a portion of the stereo wave. Sound waves are one-directional, which represent a single value (amplitude or frequency) at a given instance of time.
By taking a closer look at the word nice in the graph below, we can infer that these continuous waves are nothing but values in one direction.

These values are in the form of a list of lists (since it is a dual channel wave) when read on SciPy library in Python. Let us print the first 500 values of this wave. Each value represents the amplitude of the wave at that particular instance in time. The default sampling rate is 44,100Hz for disk quality audio. However, the process of conversion of continuous signal to discrete (values) and back to continuous signal is a fragile task. One has to keep in mind that if the output wave needs to comprise of complete continuous wave without noise or attenuation then the sampling rate should be higher than twice the largest frequency of the wave.
Digital Representation Of Audio

Both the values of a single list are equal, since the output of sound/speech on both the sides are the same. Now, let us visualize only a single channel — either left or right — to understand the wave better. After taking a look at the values of the whole wave, we shall process only the 0th indexed values in this visualisation.
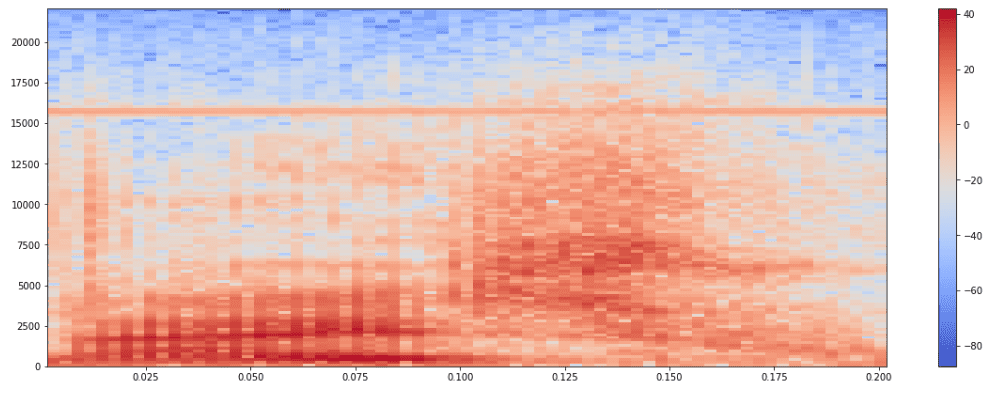
This heat map shows a pattern in the voice which is above the x-axis. A neural network will be able to understand these kinds of patterns and classify sounds based on similar patterns recognised. Let us consider a Recurrent Neural Network, an LSTM (Long Short-Term Memory), which helps us to store past patterns, and feed them back into the neural network to help us train the present pattern for better understanding the voice.
What are LSTM Neural Networks?
The LSTM is a network of cells where these cells take input from the previous state ht-1 and current input xt. The main function of the cells is to decide what to keep in mind and what to omit from the memory. The past state, the current memory and the present input work together to predict the next output. The LSTM networks are popular nowadays because of their accurate performance in language processing tasks.

Source: http://karpathy.github.io/2015/05/21/rnn-effectiveness/
Let us take an example of the word, “nice” again, which consists of four letters, which is being pronounced in one second. That would be N-N-I-I-C-C-C-E-E-E for the neural network to understand the voice or the audio sample for each segment of the audio clip representing each letter. Once all of these segments are pushed on to a neural net, it would understand and classify the word as NICE. This is possible if the past letters are considered to spell N-I-C-E by keeping in memory of the previous letter. Similarly, the voice bands of the past are considered to understand the pattern of the word WORK.
Understanding Audio Segments
A set of inputs containing phoneme (a band of voice from the heat map) from an audio is used as an input. This network will compute the phonemes and produce a phonetic segment with the likelihood of an output. Below is a set of bands from our voice sample.

Once the model is trained with the help of supervised learning to classify the audio or voice sample to a specific class, these neural networks can be extended to perform the speech-to-text conversion, which is implemented in today’s mobile assistants.
Conclusion
With the understanding of how to process sound on a machine, one can also work on building their own sound classification systems. But when it comes to deep learning, the data is the key. Larger the data, better the accuracy.















































































