



Deep learning has gained many achievements over the past few years, right from defeating professionals in poker games to autonomous driving. Accomplishing such tasks needs a complex methodology which will result in a complex system. Even now, there are many cases where the researchers are applying a trial-and-error method to build certain models.
With the increasing demand in deep learning, the demand for better as well as sophisticated hardware has also increased. Several Tier I organisations like Intel, Nvidia and Alibaba, among others, are striving hard to bridge the gap between the software and hardware. The only way to build a sophisticated deep learning model is to use better hardware.
Recently, researchers from Harvard University came up with one such idea of developing a systematic and scientific approach to platform benchmarking. According to the researchers the benchmarking should not only compare the performance of different platforms which is running a broad range of deep learning models, but also support deeper analysis of the interactions across the spectrum of different model attributes (eg, hyperparameters), hardware design choices, and software support.
ParaDnn, a parameterised deep learning benchmark suite is introduced by the researchers of Harvard University. This suite generates end-to-end models for fully connected (FC), convolutional neural network (CNN), and recurrent neural networks (RNN).
Behind The Suite
In ParaDnn, the model types cover 95% of Google’s TPU workloads, all of Facebook’s deep learning models, and eight out of nine MLPerf models. The image classification/detection and sentiment analysis models are the CNNs, the recommendation and translation models are FCs, the RNN translator and another version of sentiment analysis are the RNNs. In addition to ParaDnn, the researchers also included two workloads written in TensorFlow from MLPerf and they are transformer and ResNet-50.
The researchers compared three hardware platforms as mentioned below
- The Tensor Processing Unit (TPU) v2 and v3 where each TPU v2 device delivers a peak of 180 TFLOPS on a single board and TPU v3 has an improved peak performance of 420 TFLOPS.
- The NVIDIA Tesla V100 Tensor Core which is a GPU with Volta architecture.
- CPUs, considered as a suitable and important platform for training in certain cases.
How It Works
Enabled by ParaDnn, the researchers specially marked the insights of these platforms. They made a deep dive into the TPU v2 and v3 which helps in revealing the architectural bottlenecks in computation capability, memory bandwidth, multi-chip overhead, and device-host balance.
The architecture of ParaDnn CNNs is
Input → [Residual/Bottleneck Block]×4 → FC → Output.
The architecture of ParaDnn FC is
Input → [Layer[Node]] → Output, where the layer is the number of layers is variables.
The architecture of ParaDnn RNN is
Input → [RNN/LSTM/GRU Cell] → Output
The ranges of the hyperparameters and dataset variables are given below
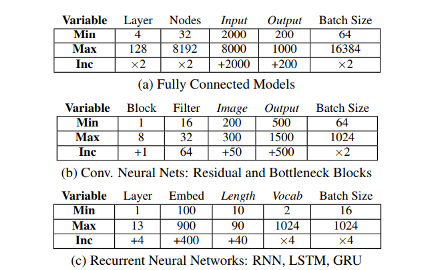
Advantages Of ParaDnn
ParaDnn seamlessly generates more than a thousand of parameterised multi-layer models, comprising fully-connected models (FC), convolutional neural networks (CNN), and recurrent neural networks (RNN). It allows a systematic benchmarking across almost six orders-of-magnitude of model parameter size, exceeding the range of existing benchmarks.
How This Suite Is Different From Existing Suites
In deep learning, there are already two types of existing benchmark suites. One is real-world benchmark suites such as MLPerf, Fathom, BenchNN, etc. The other is micro-benchmark suites, such as DeepBench and BenchIP. The drawback of the real-world suites is that it contains a handful of popular and current deep learning models spanning a variety of model architectures which means that it may become obsolete in future as this technology is evolving in a very fast manner. Furthermore, these suites fail to reveal deep insights into interactions between DL model attributes and hardware performance.
ParaDnn has all the advantages to the above shortcomings. It provides large end-to-end models covering current and future applications as well as parameterising the deep learning models to explore a broader design space of deep neural network model attributes. This suite also has the ability to gain insights about hardware performance sensitivity to model attributes by allowing interpolating and extrapolating to future models of interest.
TPU vs GPU vs CPU: A Cross-Platform Comparison
The researchers made a cross-platform comparison in order to choose the most suitable platform based on models of interest. This can also be said as the key takeaways which shows that no single platform is the best for all scenarios. They are mentioned below
- TPU: Tensor Processing Unit is highly-optimised for large batches and CNNs and has the highest training throughput.
- GPU: Graphics Processing Unit shows better flexibility and programmability for irregular computations, such as small batches and nonMatMul computations.
- CPU: Central Processing Unit achieves the highest FLOPS utilisation for RNNs and supports the largest model because of large memory capacity.
Outlook
It has been shown that different platforms offer advantages for different models based on their respective characteristics. Emerging technology is evolving at a very fast pace and for this reason, it is also crucial to keep updating the benchmarking continuously. Moreover, for future work, the researchers will be working on studying deep learning inference, cloud overhead, multi-node systems, accuracy, or convergence.














































































