




With images becoming the fastest growing content, image classification has become a major driving force for businesses to speed up processes. Rapid advances in computer vision and ongoing research has allowed enterprises to create solutions that enable automated image tagging and automatically add tags to images to allow users to search and filter more quickly.
Enterprises that want to add more value to existing visual content or e-commerce businesses that deal with multiple product photos in a digital asset management (DAM) system or a web content management (WCM) environment used by an editorial staff on daily basis rely on image classification techniques to speed up business processes.
It all started with Google Cloud’s Fei Fei Li and Director of the Stanford Artificial Intelligence Lab and the Stanford Vision Lab who built ImageNet – a dataset originally published as a research paper in 2009 which evolved into an algorithmic competition to find out which algorithms could identify objects in images with the least error rate. The paper presented a new online database, a large-scale ontology of images that offers offers unparalleled opportunities to researchers in the computer vision community and serves as a catalyst for the AI boom. The annual ImageNet (image recognition) competition has improved the accuracy of classifying images and its winning researchers have donned on senior roles at Google, Baidu and Google-owned London-based DeepMind.
Given the explosion of image data and the application of image classification research in Facebook tagging, land cover classification in agriculture and remote sensing in meterology, oceanography, geology, archaeology and other areas — AI-fuelled research has found a home in everyday applications.
In this article, we list down top research papers dealing with convolutional neural networks and their resulting advances in object recognition, image captioning, semantic segmentation and human pose estimation.
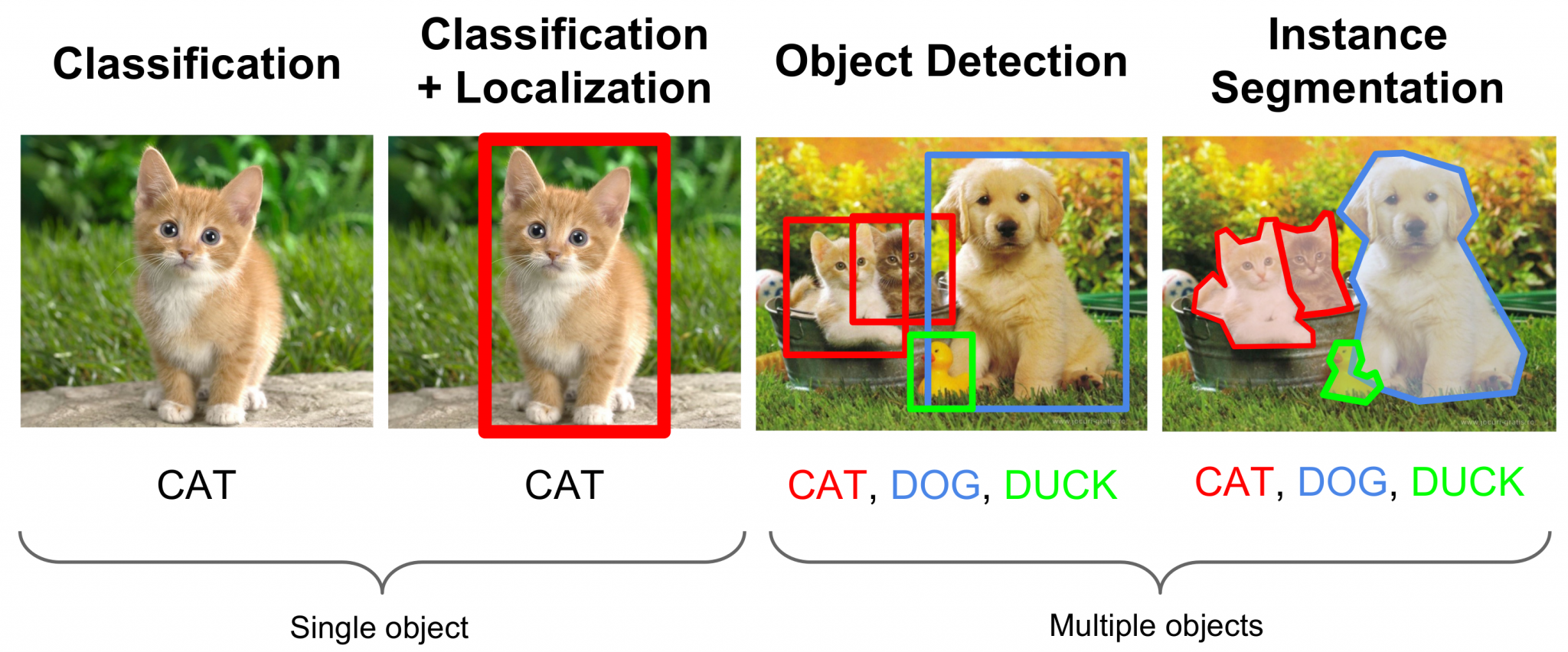
Analytics India Magazine lists down the top 5 research papers in image classification
Dubbed as one of the milestones in deep learning, this research paper “ImageNet Classification with Deep Convolutional Neural Networks” started it all. Even though deep learning had been around since the 70s with AI heavyweights Geoff Hinton, Yann LeCun and Yoshua Bengio working on Convolutional Neural Networks, AlexNet brought deep learning into the mainstream. Authored by Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton, this 2012 paper won the ImageNet Large Scale Visual Recognition Challenge with a 15.4% error rate. In fact, 2012 marked the first year when a CNN was used to achieve a top 5 test error rate of 15.4% and the next best research paper achieved an error rate of 26.2. the paper was ground-breaking in its approach and brought the many concepts of deep learning into the mainstream.
Inspired by the Inception thriller, GoogleNet proposes a deep convolutional neural network architecture codenamed “Inception”, which was responsible for setting the new state of the art for classification and detection in the ImageNet Large-Scale Visual Recognition Challenge. This Google project proposed a 22 layer convolutional neural network and was the winner of ILSVRC 2014 with an rate of 6.7%. according to experts, this CNN architecture was the first to propose a different approach from the general approach of simply stacking and pooling layers on top of each other.
Developed in response to index images, GoogleNet research project was undertaken by Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Drago Anguelov, Dumitru Erhan, Andrew Rabinovich and Christian Szegedy. At the core of the project was a reworked convolutional network architecture consisting of 100+ layers with a depth of 20 parameter layers) and is based Hebbian principle and scale invariance. Over the years, Google has been experimenting with neural networks to improve its image search ability and understand the content within Youtube videos.Google is leveraging these research advances and converting it into Google products such as in YouTube, image search and even self-driving cars.
This research paper authored by Matthew D Zeiler and Rob Fergus introduced a novel visualization technique that gave a peek into the functioning of intermediate feature layers and the operation of the classifier. This architecture was trained on 1.3 million images and it developed a visualization technique called De Deconvolutional Network that helped to examine different feature activations and their relation to the input space. The paper proposed to outperform Krizhevsky on the ImageNet classification benchmark.
Regularizing deep networks using efficient layerwise adversarial training (2017)
This research paper, authored by two University of Maryland researchers Rama Chellappa, Swami Sankaranarayanan and GE Global researchers Arpit Jain and Ser Nam Lim proposed a simple learning algorithm that leveraged perturbations of intermediate layer activation to provide a stronger regularization while improving the robustness of deep network to adversarial data. The research dealt with the behaviour of CNNs as related to adversarial data and the intrigue it had generated in computer vision. However, the effects of adversarial data on deeper networks had not been explored well. The paper cited results of adversarial perturbations for hidden layer activations across different samples and leveraged this observation to devise an efficient adversarial training approach that could be used to train deep architectures.
Residual Attention Network for Image Classification (2017)
As the name implies, this latest research paper proposed a “Residual Attention Network” – a convolutional neural network that leverages attention mechanism which can incorporate feed forward network architecture in an end-to-end training fashion. Authored by Fei Wang, Mengqing Jiang, Chen Qian, Shuo Yang, Cheng Li, Honggang Zhang, Xiaogang Wang, Xiaoou Tang, their research methodology achieved a 0.6% top-1 accuracy improvement with 46% trunk depth and 69% forward FLOPs comparing to ResNet-200. The experiment also demonstrates that the neural network is robust vis-à-vis noisy labels.

















