




With artificial intelligence being implemented in almost every sector, it is important to understand the maths behind how it functions so accurately. Activation functions are at the end of every hidden layer of a neural network and it plays a key part in updation of weights. The main function is to introduce a non-linearity in the model, calculate, and decide what has to be sent to the output and what needs to be discarded.
In this article we will try to understand the maths behind these functions and test out some examples in Python. The graphs are plotted with the help of Matplotlib library in Python. These other activation functions are in development on neural networks in the current industry.
Softmax Function
Softmax function is an activation which returns the probability of the particular sample with respect to the other samples. This activation function is mostly used in classification problems to find the class with the highest probability.

It squashes the values between 0 and 1. The larger negative values usually tend to zero and larger positive values are inclined towards 1. Let us take a look at one of the examples of this function:
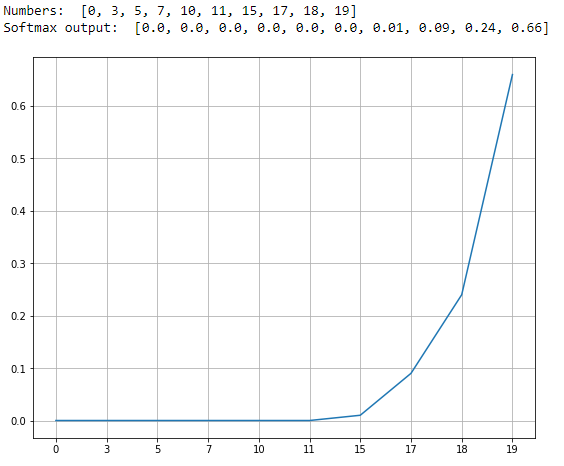
Softsign Function
The Softsign function is an activation function which rescales the values between -1 and 1 by applying a threshold just like a sigmoid function. The advantage, that is, the value of a softsign is zero-centered which helps the next neuron during propagating.

Here’s an example of a softsign function with values in between -20.0 and 20.0.
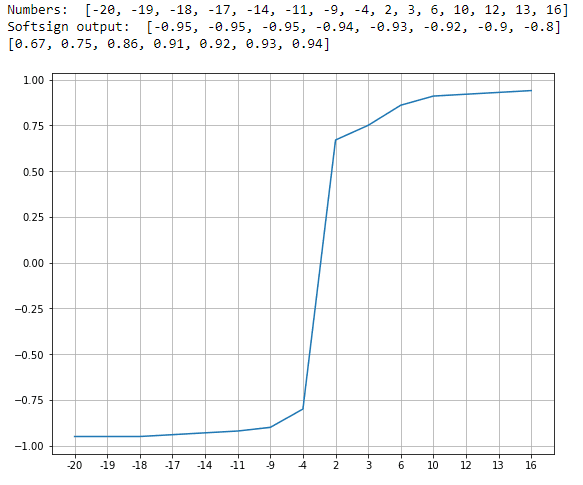
Softplus Function
This function is similar to softmax but it finds the natural logarithm. This acts like a threshold function which also decides whether to omit or let the output pass onto the other layers.
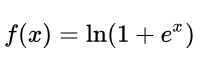
Here’s an example of softplus function. This function also squashes the negative values towards zero. Hence the function outputs a set of values which range between 0 and infinity.

Exponential Linear Unit (ELU)
An ELU is similar to a ReLU for non-negative inputs. The ELU function drops smoothly for values below 0 where as ReLU drops faster. This function is also used for faster computations comparatively. Below is the equation for ELU:

The alpha parameter in the ELU is a positive value. This can be set accordingly while manipulating the parameter of the neural network. Let us look at one of the examples of the ELU function:
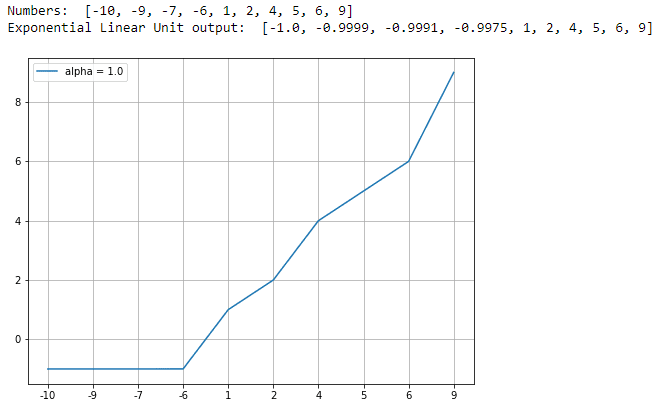
Parameter Rectified Linear Unit (PReLU)
This activation function is similar to ReLU, but contains tunable parameters like alpha, which can be configured while adjusting the parameters of the model. The values above 0 are unchanged but values below 0 are reduced by an amount ‘alpha’ to allow some negative values to be considered during training. This is done to help the loss converge at the minima smoothly.
Below is an equation of Parametric Rectified Linear Unit,

With the alpha value equal to 0.05 we shall plot a graph to visualise how the PReLU is computed.
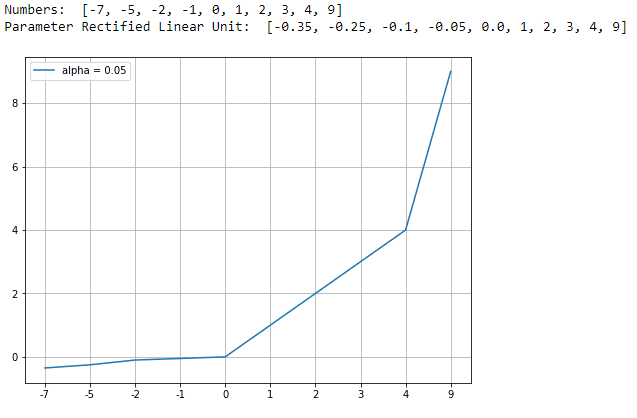
Binary Step Function
This function is one of the basic ones, but its not widely used in developing neural networks. To understand what Binary Step is, let us consider a simple equation.

This function is as simple as it looks. It converts all the values to either 0 or 1 depending the the sign. If the value is less than 0 it is assigned a value 0 but if it is greater than or equal to zero it is assigned a value of 1. Let’s look at an example of a binary step function.

Conclusion
These advanced activation functions are currently implemented in neural network development. One cannot find the perfect activation function which fits every model and produces accurate results. It completely depends on the model and how the data is behaving with respect to the model. Research is still going on in this domain to find better activation function for building robust models.
















































































