


 Automation is (back?) riding the crest of the innovation news cycle these days. Our clients and prospects often discuss with us automation solutions to their problems. Is maximizing automation from the get-go always the path to maximum value? That’s the recurring question that comes up often. Not surprising, given the current stage that the automation hype cycle is in. Automation in finance is redefining the way financial sector works.
Automation is (back?) riding the crest of the innovation news cycle these days. Our clients and prospects often discuss with us automation solutions to their problems. Is maximizing automation from the get-go always the path to maximum value? That’s the recurring question that comes up often. Not surprising, given the current stage that the automation hype cycle is in. Automation in finance is redefining the way financial sector works.
However, does the front loading of maximum (or complete) automation always drive maximum benefits? Or are there other approaches that can lead to optimal value? I discuss a real-life case that we worked on recently, where we were faced with this very question, in automation in finance.
The quest for structure in an unstructured world
The engagement was with a data and services provider in financial services. They wanted to analyze regulatory filings and other public domain content in a particular industry, extract some business and financial information from this content. This information would then be embellished and wrapped into a data product that they could sell to their clients. They wanted their data product to be rich in coverage and high on accuracy.
Other than the sale of the final product, they had engaged us to participate in the complete data end-to-end lifecycle.
This data lifecycle broadly looked like this:
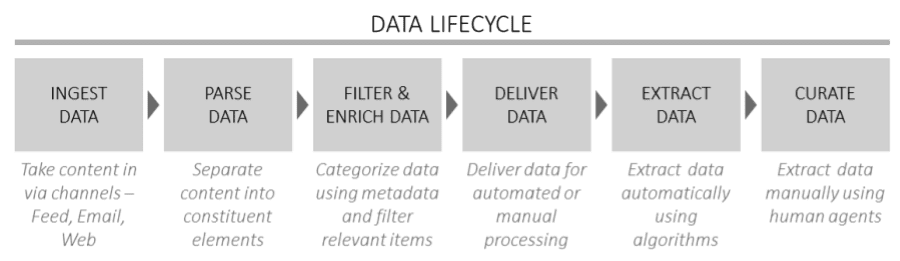
Figure 1: Data lifecycle in the engagement
The ‘raw’ content itself – regulatory filings, website content, press releases etc. – was mostly unstructured. About 5 different filing types were to be covered in the MVP (Minimum Viable Product). At the level of detail of interest to us, the filers seemed to structure their filings any way they wished, as long as they stayed within the broad formats specified by the regulator. A typical filing contained financial and other numbers (that were of interest to us) surrounded by a lot of qualifying text (only a small proportion of which was of interest).
Of course, for the website content and the press releases, there was no real structure present to the content.
A Robot Dance – It takes two to do it
Both teams were very keen to explore how automation could be leveraged to achieve our goals.
We agreed that the best way to approach the engagement was to do a quick proof of concept. This proof of concept would have two main objectives – sample and analyze the content universe in order to determine potential opportunities for automation in various parts of the data lifecycle, and secondly, determine feasibility of such automation to meet client goals of reliability, coverage and accuracy.
We built a cross-functional team to work on these objectives – a group of data analysts (familiar with the domain) to analyze the data from the sources and a group of technologists to build the automation platform. The groups, with very active client participation, would jointly build the automation strategy for the content of interest.
The team started with high level automation feasibility analysis of the content and the sources. The analysis focused on two important angles – feasibility of automation for information extraction and feasibility of automation for work delivery.
Fairly early in the analysis, complete automation in information extraction was ruled out in the short term (i.e., for the MVP), for the following reasons:
- The content was almost completely unstructured, with no significant commonality or patterns in its structure
- The information required was often found across multiple documents / filings, with insufficient linkages between them
- The need for high accuracy in output data demanded by downstream users – the output was designed to be used after delivery in an automated fashion downstream, without further edits or validations
Low hanging fruit and automated harvesting
In other words, the team reached the conclusion that it was not feasible to completely automate the data lifecycle.
However, even within this “end-to-end automation gloom”, we could identify a few bright spots. These were areas where we thought automation could make a material contribution to overall efficiency.
Some of the examples that follow are related to this specific engagement, but we have also encountered them in other conversations / engagements.
Information extraction: Going halfway
For example, there was a particular type of regulatory filing that was identified as critical by the client where we discovered some commonality of structure across different filers.
Now the amount of commonality was insufficient to automate information extraction completely. However, we found an opportunity for intermediate automation – the information would be extracted automatically, but would not be included as-is in the final product. Rather, it would be delivered to a human agent for validation. However, the agent’s work description would be changed from the grunt work of reading and form filling, to mostly validating a pre-filled form.
We also decided to deploy a Machine Learning bot here to continuously refine this extraction taking inputs from user edits, thus creating a roadmap to completely automate this extraction in the future.
In addition, we also designed what we called Agent Helpers. These were tiny snippets of code which would reside in the Workstation that we designed for (human) agents. They would help agents to navigate to critical parts of the content that were of interest in extraction, thus injecting additional efficiency in their work. (Some filings that we had in scope could easily be 15-25 pages long on an average – so, any aid in navigating this content could potentially yield significant benefits).
Work delivery: They deliver, so that we can
Information delivery (to human agents) was another area where we identified potential for automation.
One obvious application was the filtering of content – simple keyword based filtering could be used to filter out cases that were needed to be seen by an agent. We employed multiple keyword strategies depending on the content source and other parameters – filing types, topics, client names etc. Automating this was easy, and delivered an important early win.
We identified another interesting opportunity – a particular type of regulatory filing that made up the largest part of cases we had to handle, by volume. On discussion with the client, we learnt that they were interested in analyzing only ~15% of these filings. This was huge – if we could filter out the cases of interest, then we could achieve significant savings in the downstream human analysis effort.
However, the keyword filtering approach described earlier alone would not suffice for this need. So we built an automated Deep Filtering mechanism – this code would navigate to and download the actual content, look within it for certain text (specifically, the name of the subsidiary that was submitting the actual filing), and then filter out content accordingly.
The BOTtomline impact
Our automation strategy for the steady state phase of the engagement ended up looking something like this.
Automation and human agents will work together to produce the final output. The part of the data lifecycle from data intake to data delivery (to human agents) will be completely automated. Not only will agents get only relevant cases directly in their worklist without having to look at new content from every data source constantly, they will also have to investigate and work on only 16-18% of the content items from the sources because of automated keyword filtering and deep filtering approaches. This means a significant saving in agent effort in the work analysis cycle, driven by automation.
For information extraction, automation will be deployed as an agent aid – information will be auto-extracted from the content in some cases and sent through a human validation step before it will be included in the final product. This approach should not only help with the accuracy of the final output, but should improve agent efficiency in the data update step too. In conjunction with the Agent Helper feature, this can help reduce time taken by agents for certain content types by as much as 70%.
Machine learning approaches have also been initiated, but they are only expected to bear fruit in the medium term. A realistic timeframe for that is estimated to be around 6-9 months, once the system has been through enough cases to iterate and refine these approaches and build a learning database.

Figure 2: Automation strategy for MVP and steady state
The bots would like to thank…
The proof of concept has been a resounding success, and we are now discussing with the client the detailed implementation strategy and roadmap. In a way, what I have spoken about thus far are the tangible contributors to the success of our approach (overall, and to automation specifically).
During our debrief sessions, we also analyzed other contributors to success that might not have been as tangible, but were critical nonetheless.
Engagement structuring – A purely “technical” approach to the exercise would not have worked. The structure of the team (domain-aware data analysts and technologists) as well as the pre-planning (separately focus on different areas in the data lifecycle to deploy automation and then proof feasibility in those areas) ensured that an actionable automation plan could be developed and implemented.
Client participation – We had a daily call set up with the client during the proof of concept. We used it to play back our learnings to the client, discuss potential automation areas and approaches with them and get their feedback in quick time. This helped us root our assumptions and approaches to automation in our client’s business reality, rather than make them academic. It was also heartening to see senior members from the client team participating in these frequent discussions.
Trust and openness – We made it a point to be open with the client about what could be achieved in terms of automation and by when. We proactively and transparently discussed available options and approaches with them, and the potential pros and cons of each path. We were very careful not to make any unrealistic promises around automation. Our client has specifically pointed out to our transparency and openness as strong drivers that “make them want to work with our team”.
People, people, people – Innovation needs rockstars. You cannot have a team of journeymen and expect them to produce incredible work. Identify your rockstars, give them direction and goals and then, give them space. We did exactly this in this engagement, and the results speak for themselves.
In praise of pragmatic automation
In conclusion, automation is just a means to an end – the end is typically one or more business goals.
Automation can play the role of a force-multiplier in achieving the business goal(s). However, it does not help to have a dogmatic view to automation – rarely is its use an all-or-nothing question. Given the current state of automation technology, it is very likely that the solution to a problem will bring together automated and human elements. The focus of strategy should thus shift from maximizing the use of automation to finding the right mix of humans and bots to optimally solve the business problem.
In other words, finding that sweet spot between human and bot.
Authored by:
Rajesh Kamath
Head of financial services solutions and incubation at Incedo Inc.






































































