


We shall take a look at the shuffle operation in both Hadoop and Spark in this article. The recent announcement from Databricks about breaking the Terasort record sparked this article – one of the key optimization points was the shuffle, with the other two points being the new sorting algorithm and the external sorting service.
Background: Shuffle operation in Hadoop
The fundamental premise in the Map-Reduce (MR) paradigm is that the input to every reducer will be sorted by key. The process of ensuring this, i.e. transferring the map outputs to reducer inputs in sorted form is the shuffle operation.
Map Side
The map task writes output to a buffer, which is a circular memory buffer. The size of this buffer is controlled by the parameter io.sort.mb (with default value of 100mb). When buffer size exceeds the threshold, a background thread starts spilling the data to disk. The spills are written to mapred.local.dir property in a folder specific to the job. The spill threshold is specified by the parameter io.sort.spill.percent (default value is 80%). Before spilling, the background thread partitions the data such that data for each reducer is a separate partition. Both operations of writing to buffer and writing to disk are in parallel. But if the Buffer fills up, the map will block. This is beautifully illustrated in this diagram from the famous “Hadoop: The Definitive Guide” book by Tom White and published by the O’Reilly Media, Inc.
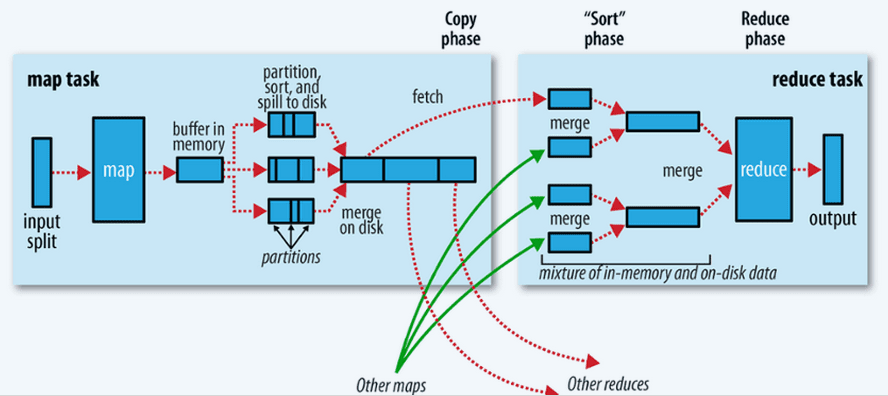
In addition, the map outputs can be compressed by setting mapred.compress.map.output parameter to “true”. Appropriate compression library can be specified in mapred.map.output.compression.codec parameter. It could be one of bzip, gzip and LZO.
The output file partitions are transferred over HTTP to the respective reducers.
Reduce Side
Reducer has a copy phase – small number of threads fetches map outputs in parallel from the respective disk of the task tracker. The no. of threads is controlled by the parameter mapred.reduce.parallel.copies (with default of 5). The reducers know from which task tracker to read the partition files – this is specified in the heartbeat communication from the map jobs to the tasktracker, which in turn notifies the jobtracker.
The map outputs are copied to the memory Buffer of the reducer side tasktracker – the size of this Buffer is controlled by the parameter mapred.job.shuffle.input.buffer.percent, which is the percentage of the heap to be used. If the threshold size specified by the parameter mapred.job.shuffle.merge.percent is exceeded or if the threshold number of map outputs specified by the parameter mapred.inmem.merge.threshold, the Buffer is spilled to disk. A background thread merges them into larger sorted files. The compressed map outputs must be necessarily decompressed at this stage.
When all map outputs have been copied, the reducer moves into the sort phase. The reduce inputs are merged maintaining the sorted order. The number of rounds required for the merge is controlled by the merge factor specified in the io.sort.factor property (default value is 10). The number of map outputs divided by the merge factor is the number of rounds required.
The final phase of the reducer is a reduce phase, which feeds in directly the output from the rounds respectively to a reduce function. The function is invoked on the key in the sorted output and the results are written to HDFS directly.
Shuffle operation in Hadoop YARN
Thanks to Shrey Mehrotra of my team, who wrote this section.
Shuffle operation in Hadoop is implemented by ShuffleConsumerPlugin. This interface uses either of the built-in shuffle handler or a 3rd party AuxiliaryService to shuffle MOF (MapOutputFile) files to reducers during the execution of a MapReduce program.
AuxiliaryService is a framework which allow per-node customer services required for a running the applications over YARN. The Auxiliary Service is managed by NodeManager. It is notified when a new application or a new container gets started or gets completed. It also provides a handle to retrieve the Metadata for the MapReduce services in Hadoop. For ex. The metadata can be the connection information between a mapper and a reducer to transfer MOF files during MapReduce job execution.
ShuffleHandler is the extension of AuxiliaryService which is used by Hadoop MapReduce. It is started as a service and provides shuffle implementation for Maps Output. This implementation is enabled by providing following properties in yarn-site.xml.

| <property><name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value> </property>
<property> <name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> |
Shuffle Operation in Spark
The shuffle operation is implemented differently in Spark compared to Hadoop.
Map Side
Each map task in Spark writes out a shuffle file (operating system disk buffer) for every reducer – this corresponds to a logical block in Spark. These files are not intermediary in the sense that Spark does not merge them into larger partitioned ones. Since scheduling overhead in Spark is much lesser, the no. of mappers (M) and reducers(R) is far higher than in Hadoop. Thus, shipping M*R files to the respective reducers could result in significant overheads. We shall see how researchers have optimized these.
Similar to Hadoop, Spark also provide a parameter (spark.shuffle.compress) to specify compression libraries to compress map outputs. In this case, it could be Snappy (default) or LZF. Snappy uses only 33KB of buffer for each open file and significantly reduces risk of encountering out-of-memory error.
Reduce Side
A major difference between Hadoop and Spark is on the reducer side – Spark requires all shuffled data to fit into memory of the corresponding reducer task (we saw that Hadoop had an option to spill this over to disk). This would of course happen only in cases where the reducer task demands all shuffled data for a GroupByKey or a ReduceByKey operation, for instance. Spark throws an out-of-memory exception in this case, which has proved quite a challenge for developers so far.
The other key difference between Hadoop and Spark is that there is no overlapping copy phase in Spark (We saw that Hadoop has an overlapping copy phase where mappers push data to the reducers even before map is complete). What this means is that the shuffle is a pull operation in Spark, compared to a push operation in Hadoop. Each reducer should also maintain a network buffer to fetch map outputs. Size of this buffer is specified through the parameter spark.reducer.maxMbInFlight (default is 48MB).
Optimizations
It does look like Hadoop shuffle is much more optimized compared to Spark’s shuffle from the discussion so far. However, this was the case and researchers have made significant optimizations to Spark w.r.t. the shuffle operation. The two possible approaches are 1. to emulate Hadoop behavior by merging intermediate files 2. To create larger shuffle files 3. Use columnar compression to shift bottleneck to CPU.
Emulation of Hadoop behavior may be too expensive (time consuming) in Spark – mainly because it requires a second full pass over all shuffle data. It would also be more involved in terms of modifications required to Spark.
Columnar compression is not easy to apply due to general data model of Spark – data are arbitrary types, only need to be serializable. An attempt at this was made in [1] by assuming primitive data types and Java objects are used during the shuffle phase. However, they found that compressibility was low and involves significant computation and metadata maintenance for splitting data into columns on map side and reconstructing them into rows on reduce side. Here one may want to investigate further things like use of column-oriented reduction algorithms like the kind presented in C-store [2].
The researchers have implemented shuffle file consolidation (the ability to create larger shuffle files) by maintaining a shuffle file per core, rather than per map task – implying all map tasks sharing a core will use the same shuffle file. This gives rise to CR no. of shuffle files, where C is no. of cores and R is no. of reducers. Without consolidation, the no. of shuffle files will be MR, where M is the no. of mappers. Since the number of mappers and reducers in Spark is way higher (due to less overhead in creating mappers/reducers) compared to Hadoop, M*R tends to be too high, resulting in poor performance. Performance studies showed that Spark was able to outperform Hadoop when shuffle file consolidation was realized in Spark, under controlled conditions – specifically, the optimizations worked well for ext4 file systems. This leaves a bit of a gap, as AWS uses ext3 by default. Spark performs worse in ext3 compared to Hadoop.
The optimized shuffle operation can be illustrated as in figure below:

Authors:
Dr. Vijay Srinivas Agneeswaran, Director, Big Data Labs, Impetus Infotech India Pvt. Ltd. Email: vijay.sa@impetus.co.in
Shrey Mehrotra, Software Engineer, Big Data Labs, Impetus Infotech India Pvt. Ltd. Email: shrey.mehrotra@impetus.co.in







































































