


Deep learning models rely on collecting high-quality data at scale to be successful with training. Some of the popular use cases are that of Amazon or Myntra, that use image processing techniques to classify the products based on the information present in the image.
Any machine learning pipeline contains many auxiliary tasks, which often require more engineering work than the model design itself. Tasks like data collection, cleaning, crowdsourcing, versioning, dataset storage and taxonomy management, are some of the examples.
Even though the recommendation systems have evolved over time, real-time (< 100 milliseconds) large scale application is still a challenging task for the online platforms. And, Pinterest’s Pixie is one of the best solutions available out today.
A Look At Pinterest Voyager – Hub For Storing CV Data
Recommendation systems are the cornerstone of a majority of the modern day billion dollar industries. From Amazon to Netflix to Pinterest. Amazon recommends commodities for its e-commerce website and Netflix has a limited number of movies to recommend but in the case of Pinterest, the numbers are not that small. It has more than 100 billion ideas saved and has to deliver to more than 200 million of its users in real time.
Pinterest’s Pixie uses 3 billion nodes and 17 billion edges and the results show that the user interaction has increased up to 50% when compared to a Hadoop-based production system.
Computer Vision plays a key role in Pinterest’s everyday business. It is used in enabling search and discovery from every Pin and every image within a Pin.
To carry out the tasks like label cleaning, dataset storage as discussed above, Pinterest engineered a solution — Voyager.
Voyager is a centralised, scalable, and flexible data management tool. It serves as a hub for storing computer vision training data. It helps in the initial stages of data exploration where only a small dataset is required.
For e-commerce platform defining taxonomy is crucial. And, Voyager enables a quick way to define just with the help of text search.
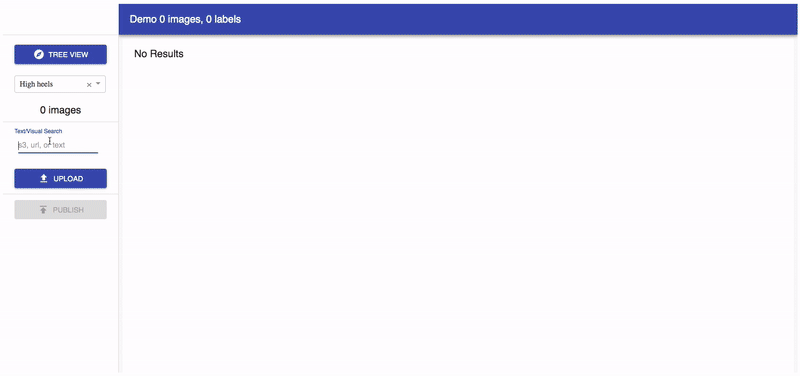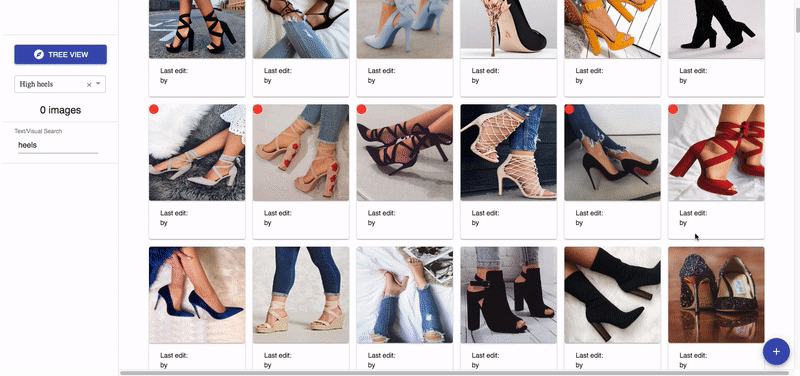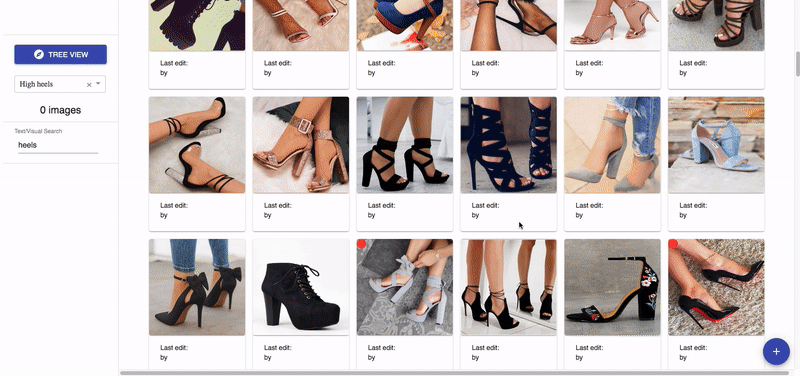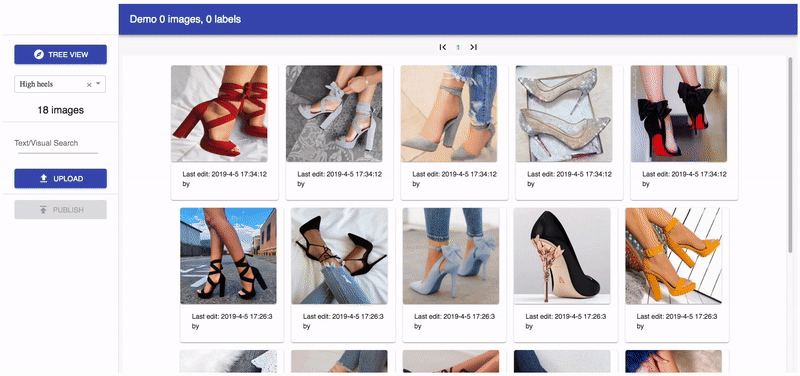
Voyager is not just a web tool. It is also a system that handles data collection, cleaning, visualisation, and deep vision model training. This system is supported by an underlying unified data labelling schema.
This success of this schema owes to the following factors:
- Each image can have image-level labels and region-level labels A region can be defined as a box, a mask, a polygon, etc.
- Any region can have a label set from several independent taxonomies (e.g., semantic category, colour palette, material, pattern, etc).
- Relating a region to regions in other images (e.g., this couch in this living room scene is similar to that couch in the other living room scene).
- Record labels from taxonomies that have no spatial associations in the image
- Images need to be co-located as raw bytes with the metadata, not linked, to protect against relocated or modified images.
Conclusion
One thing that can be learned from Pinterest is that their data management system significantly simplifies common deep learning tasks by reducing turnaround time for the process of data collection, model training, debug, and more data collection. This is important for any developers who plan on building platforms with computer vision tasks as the vision tasks get more complicated over the duration of product deployment.
This article draws information from Pinterest Engineering blog.















































































