






Reinforcement learning is a technique in building an artificial intelligent network where an agent is allowed to play or run by itself, correcting its movements and outputs every time it makes a mistake. The computation power and training time required solely depends on the type of problem we are trying to solve by building a model.
OpenAI gym is an environment where one can learn and implement the Reinforcement Learning algorithms to understand how they work. It gives us the access to teach the agent from understanding the situation by becoming an expert on how to walk through the specific task.
In this article, we will be working on the Frozen Lake environment where we teach the agent to move from one block to another and learn from the mistakes.
Introduction
In the Q-Learning method of reinforcement learning, the value is updated by an off-policy. A greedy action is allowed during training which helps the agent explore the environment. Greedy action refers to letting a random action or movement to occur which then allows the agent to explore the unseen block. The advantage of off-policy over on-policy is that the model will not get trapped at the local minima.
The Frozen Lake environment is a 4×4 grid which contain four possible areas — Safe (S), Frozen (F), Hole (H) and Goal (G). The agent moves around the grid until it reaches the goal or the hole. If it falls into the hole, it has to start from the beginning and is rewarded the value 0. The process continues until it learns from every mistake and reaches the goal eventually. Here is visual description of the Frozen Lake grid (4×4):
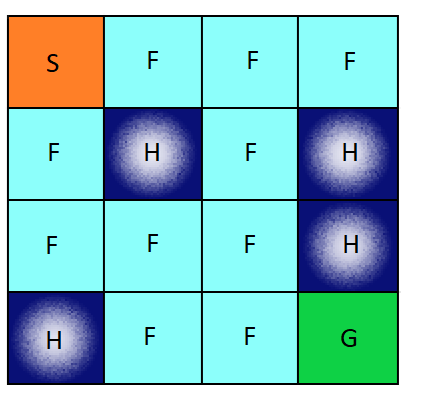

The agent in the environment has four possible moves — Up, Down, Left and Right. We will be implementing one of the Reinforcement Learning techniques, Q-Learning, here. This environment will allow the agent to move accordingly. There could be a random action happening once every a few episodes — let’s say the agent is slipping in different directions because it is hard to walk on a frozen surface. Considering this situation, we need to allow some random movement at first, but eventually try to reduce its probability. This way we can correct the error caused by minimising the loss.
This grid has 16 possible blocks where the agent will be at a given time. At the current state, the agent will have four possibilities of deciding the next state. From the current state, the agent can move in four directions as mentioned which gives us a total of 16×4 possibilities. These are our weights and we will update them according to the movement of our agent.
Let us start with importing the libraries and defining the required placeholders and variables.
https://gist.github.com/analyticsindiamagazine/74a37fa53422424c3ed40b81a62b3027
Once we have all the required resources, we can start training our agent to deal with the Frozen Lake situation. At first, the random movement allows the agent to move around and understand the environment. Later, we will reduce this random action which allows the agent to move in the direction which is likely to be either a frozen state or the goal. Every episode starts with the position Safe (S) and then the agent continues to move around the grid trying new blocks. The episode ends once the agent has reached the Goal for which the reward value is 1.
Now let us build our model using Tensorflow:
https://gist.github.com/analyticsindiamagazine/381977a5831835b4c0dddbb53e6c1b70
Here is a visual representation of how the agent moves around a grid. Reward is 0 for every block but 1 if the agent reaches the goal. We will run our model for 2,000 episodes. The agent will learn the environment or try to master at about 900th episode.
Conclusion
This was the example of a simple Q-Learning technique which is an off-policy method. One can implement this method to train a model by unsupervised learning. Once the agent has learnt the environment, the model converges to a point where a random action is not required. We can trace the state at every iteration of every episode to see how the weights vary. The key in the off-policy method is the allowance of the greedy action and the move to a next state. Since we allow this action, the agent will converge faster at the local minima and learn the environment sooner than an on-policy method.


















