Bidirectional Encoder Representations from Transformers or BERT, which was open-sourced late last year, offered a new ground to embattle the intricacies involved in understanding the language models.
BERT uses WordPiece embeddings with a 30,000 token vocabulary and learned positional embeddings with supported sequence lengths up to 512 tokens. It helped explore the unsupervised pre-training of natural language understanding systems.
Now researchers at Carnegie Mellon University in association with Google Brain developed a novel architecture that makes the best use of Transformer-XL, state-of-the-art autoregressive model, into pretraining.
What Transformer XL & Autoregressive (AR) Models Offer
Transformer-XL, which was introduced earlier this month is an improvement in the state-of-the-art transformer model. It gained attention when it succeeded in learning dependencies beyond a fixed-length without disrupting the timestamps on the input.
Transformer-XL learns dependency that is 80% longer than recurrent neural networks (RNNs) and 450% longer than vanilla Transformers and is up to 1,800+ times faster than vanilla Transformers during evaluation.
Whereas, Autoregressive (AR) language modelling is used for pre-training neural networks on large-scale unlabeled text corpora.
AR language model is trained to encode a unidirectional context (either forward or backward). This is where AR modelling falls behind as an obvious gap arises between modelling and effective pre-training.
BERT contains artificial symbols like [MASK], which result in discrepancies during pre-training. In comparison, AR language modelling does not rely on any input corruption and does not suffer from this issue.
AR language modelling and BERT possess their unique advantages over the other. And XLNet is a by-product of the search for a pre-training objective that brings the advantages of both while avoiding their flaws.
Overview Of XLNet
The authors of this work flaunt the effectiveness of XL Net with the following objectives:
- Instead of using a fixed forward or backward factorization order as in conventional AR models, XLNet maximizes the expected log-likelihood of a sequence with respect to all possible permutations of the factorization order.
- As a generalized AR language model, XLNet does not rely on data corruption. Hence, XLNet does not suffer from the pre-train-finetune discrepancy that BERT is subject to. Meanwhile, the autoregressive objective also provides a natural way to use the product rule for factorizing the joint probability of the predicted tokens, eliminating the independence assumption made in BERT.
- XLNet integrates the segment recurrence mechanism and relative encoding scheme of Transformer-XL into pretraining, which empirically improves the performance especially for tasks involving a longer text sequence.
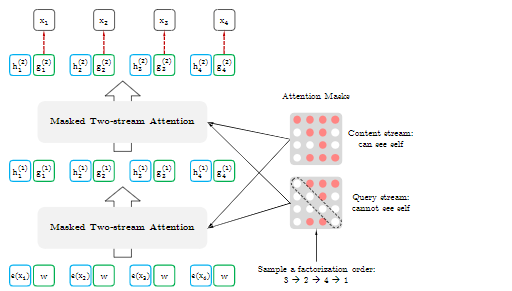
Permutation model which seems to be a recurring theme throughout this paper is an approach to make use of a permutation operation during training to pick contexts that consists of tokens from both left and right; a bidirectional approach.
To achieve this permutation, XLNet keeps the original sequence order, uses positional encodings, and relies on a special attention mask in Transformers networks.
Here is a look at how XLNet outperforms BERT by capturing more important dependencies between prediction targets
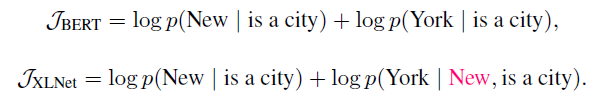
For pretraining, the authors followed BERT and used English Wikipedia containing 13 GB of plain text along with Giga5, CommonCrawl and ClueWeb 2012-B.
The sequence length and memory length are set to 512 and 384 respectively. XLNet-Large is trained on 512 TPU v3 chips for 500K steps with an Adam optimiser, linear learning rate decay and a batch size of 2048, which takes about 2.5 days.
Key Takeaways From The Paper
- XLNet is a generalized AR pretraining method that uses a permutation language modelling objective to combine the advantages of AR and auto encoding (AE) methods.
- XLNet achieves state-of-the-art results in various tasks with substantial improvement.
- XLNet-Base models outperform both BERT and the DAE trained Transformer-XL across tasks, showing the superiority of the permutation language modelling objective.
Read the full paper here.