



Hardware acceleration has taken centre stage at leading tech majors. For instance, Google’s TPU or NVIDIA’s DGX enable parallelism by providing faster interconnections between the accelerators.
An average ImageNet resolution is 469 x 387 and it has been proven that by increasing the size of an input image, the final accuracy score of a classifier increases. To fit the current accelerator memory limits, most models are made to process images of sizes 299 x 299 or 331 x 331.
Sandia National Laboratories introduce Whetstone, a method to bridge the gap by converting deep neural networks to have discrete, binary communication. It was developed with the Sandia National Laboratories’ Laboratory Directed Research and Development (LDRD) Program under the Hardware Acceleration of Adaptive Neural Algorithms Grand Challenge project and the DOE Advanced Simulation and Computing program.
Large networks need more space as they consist of more parameters. The storage capacity becomes an issue in applications like processing of information in self-driving cars and smartphones.
Currently, accelerators like NVIDIA’s Volta and Intel’s Nervana are few architectures with dedicated Tensor Core which target the deep neural network inferences for operations like multiply and accumulate.
But the researchers at Sandia wanted to fully capture the emerging landscape of deep learning architectures by addressing optimal network performance mathematically by using low-precision weights and discrete activation functions.

This is where neuromorphic hardware has come into picture. IBM’s TrueNorth is one which has managed to achieve low-power performance by coupling spike-based data representations.
The researchers at Sandia were able to achieve network configuration for a spiking hardware target with less loss. These networks used single time step binary communication unlike other spike-based coding schemes.
To demonstrate the effectiveness and reliability of Whetstone, the researchers used popular image classification datasets like MNIST, fashion MNIST, CIFAR and others for comparisons.
For neuromorphic hardware to work effectively, it is essential to convert an ANN to a SNN(spiking neural network).
The word ‘spiking’ is synonymous with the action potential of biological neurons.
In SNN, when a spike occurs, a key state variable gets communicated. The SNNs, at minimum, requirews neurons only communicate a discrete event or nothing. Either ‘1’ or nothing.
Architecture Of Whetstone
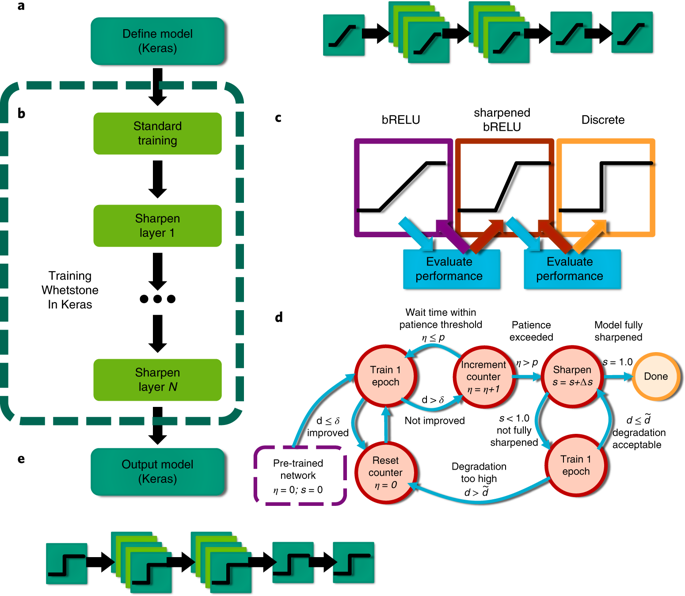
The neuron activation functions are adjusted during training (green inset), by approximating the spiking behaviour of a neural network.
The sharpening process is automated using an adaptive sharpening schedule (blue inset).
While testing for adequacy of the output layers for 1, 2,4,8 and 16-hot encoding, the researchers found that any classes which represent a dead node introduce a misclassification which resulted in a 10% penalty on the MNIST.
Whereas, 4 hot encoding surpassed the performance levels of 8 and 16-hot.
To avoid the dead nodes, the researchers tried to replace bRELU with a sigmoid layer followed by a softmax function because bRELU will result in dead nodes upon sharpening.
Read more about Whetstone’s architecture here
Installation
pip install whetstone
A sample code using Whetstone To Classify MNIST dataset in Python:
import numpy as np import keras from keras.datasets
import mnistfrom keras.models
import Sequential from keras.utils
import to_categorical from keras.layers
import Dense from whetstone.layers
import Spiking_BRelu, Softmax_Decode
from whetstone.utils importkey_generator
numClasses = 10 (x_train, y_train),(x_test, y_test) =
mnist.load_data()
y_train = to_categorical(y_train, numClasses) y_test =
to_categorical(y_test, numClasses)
x_train = np.reshape(x_train, (60000,2828)) x_test =
np.reshape(x_test, (10000,2828))
key = key_generator(10,100)
model = Sequential() model.add(Dense(256, input_shape=(28*28,)))
model.add(Spiking_BRelu()) model.add(Dense(64))
model.add(Spiking_BRelu()) model.add(Dense(10))
model.add(Spiking_BRelu()) model.add(Softmax_Decode(key))
simple = SimpleSharpener(5,epochs=True)
model.compile(loss=’categorical_crossentropy’, optimizer=’adam’) m
odel.fit(x_train,y_train,epochs=15,callbacks=[simple],metrics=[‘ac
curacy’])
print(model.evaluate(x_test,y_test))
Check the full documentation here
Key Takeaways
- Offer “off-the-shelf” capability for machine learning practitioners to convert their deep neural network approaches to a spiking implementation suitable for neuromorphic hardware
- The choice of SGD optimizer has a significant impact on spiking accuracy.
- The inclusion of batch normalization (right) allows for far less degradation over the same sharpening requirements
- This approach does not yet fully take advantage of other aspects of spike-based representations that potentially offer substantial savings in power efficiency.
- For applications such as video processing in which relevant information exists across frames, the ability for spiking neurons to integrate over time may prove useful
The compatibility of Whetstone with several non-classification neural networks applications like autoencoders makes it more prone to adoption .
Next generation of AI technologies should be able to comprehend commands by working on the huge background of information in a fast paced environment. To make these machines smart, we need to enhance the capabilities on the hardware side as well to make them more energy efficient.












































































