


 For speech recognition systems, a change in the accent can be confusing. Words under the influence of local languages sound different and a typical homepod device can mistake an Asian speaking English or even something as native as a thick Irish accent.
For speech recognition systems, a change in the accent can be confusing. Words under the influence of local languages sound different and a typical homepod device can mistake an Asian speaking English or even something as native as a thick Irish accent.
Deep Learning algorithms are the work horses behind these devices. The training data on which the models were trained could have been acquired from a single region where variations are negligible. For instance, in India, though Hindi is widely popular, the accent of a Bengali will be in stark contrast to that of a Malayali speaking Hindi. Collecting data that caters to intricacies of such native language influences can be tricky and tedious.
In order to address the shortcomings of speech recognition systems, researchers at Stanford came up with a novel architecture and the experimental results show that the model has performed well in identifying the differences.
A Brief Intro To Speech Recognition Systems
The first step in any automatic speech recognition system is to extract features i.e. identify the components of the audio signal that are good for identifying the linguistic content and discarding all the other stuff which carries information like background noise, emotion etc.
MFCCs is something one would come across while designing ASR systems. A minimal understanding of MFCCs would give an idea about its usage in the next section of this article. Mel Frequency Cepstral Coefficients (MFCCs) are a feature widely used in automatic speech and speaker recognition.
Whereas, Mel cepstral distortion (MCD) is a measure of how different two sequences of mel cepstra are. It is used in assessing the quality of parametric speech synthesis systems, including statistical parametric speech synthesis systems, the idea being that the smaller the MCD between synthesized and natural mel cepstral sequences, the closer the synthetic speech is to reproducing natural speech
The main point to understand about the speech is that sounds generated by a human are filtered by the shape of the vocal tract including tongue, teeth etc. This shape determines what sound comes out. If the shape is determined accurately, this would give an accurate representation of the phoneme being produced. The shape of the vocal tract manifests itself in the envelope of the short time power spectrum, and the job of MFCCs is to accurately represent this envelope.
Overview of The Model

The authors in their paper propose a methodology for accent conversion that learns differences between a pair of accents and produces a series of transformation matrices that can be applied to extracted Mel Frequency Cepstral Coefficients. This is accomplished with a feed forward artificial neural network, accompanied by alignment preprocessing, and validated with MCD and a softmax classifier.
For simplicity of development and due to available training data, the researchers trained and tested the model on the English language with American, Indian, and Scottish accents, for both genders.
The authors extracted 25 mel cepstral coefficients from each 5ms frame with 100 frequency bands in each of the training samples and paired samples of identical utterances in two different accents for the source and target data into the system. Each feature vector was zero-padded or truncated to the same length, which we set to be 1220 frames per sample. After extracting the MFCCs, the source and target were aligned using FastDTW.
Alignment is necessary because people speak at different rates and without alignment it is much harder for the system to identify which differences are due to accent and which are due to rate of speech.
The dataset used for the experiment consists of 1150 samples of text spoken by men with American, Canadian, Scottish, and Indian accents, and a woman with an American accent.
The final model used Adam optimization to minimize mean squared error over 5,000 epochs with batch size 16. Basic gradient descent was tried initially, later TensorFlow’s MomentumOptimizer and then Adam Optimization was used.
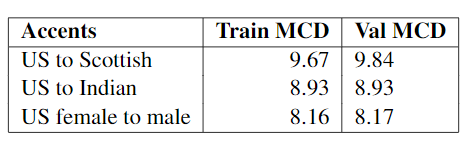
The results show that the classifier achieved 92.9% accuracy in binary classification on the benchmark American English versus Scottish English task, significantly outperforming the 68% accuracy of a Naive Bayes classifier and 76% accuracy of a Support Vector Machine classifier for the same problem.
The model also achieved MCDs below 10 for all three of the conversions that were attempted.
Voice conversion is an active area of research, but the majority of papers on the subject focus on modifying the voice itself, not the pronunciation
The success of the models such as discussed above demonstrate that it is possible to reconstruct a speech sound and make the speech recognition systems more flexible with varying accents.
For further reading:













































































