




Question Answering is one of the most interesting and oldest tasks in Artificial Intelligence. The whole quest for AI started with the challenge of solving the Question Answering problem. Many approaches and systems have been proposed to solve the task of QA.
The researchers at Allen Institute for Artificial Intelligence presented a new question set, text corpus, and baselines assembled to encourage AI research in advanced QA. The two of them are called AI2 Reasoning Challenge (ARC) which need very powerful reasoning systems to solve the challenge. The Turing test is still a fascination for many AI researchers and there is a great industry demand for intelligent QA systems as well. They are, after all, the engine of virtual assistants and helpers. The ARC test is a great challenge to check the advancements in AI and if our systems are at least as smart as the 5th graders.
QA Tasks And Questions
The importance of datasets in the progress in AI is tremendous. Although there has been progress in system performances in QA tasks, the models have been largely been retrieval based. Some common sense knowledge of the data and the task could have been useful for models. But unfortunately such advanced methods of text understanding and comprehension are not still studied. Thus ARC throws a challenge to the scientific community by throwing questions that are hard to answer.
Many tests for AI involve a wide variety of linguistic and inferential phenomena, have varying levels of difficulty, and are measurable. But to obtain such a level is difficult. Following the tradition, the team has put in several months of extensive search. Two examples of challenge questions are:
Which property of a mineral can be determined just by looking at it?
(A) luster [correct] (B) mass (C) weight (D) hardness
A student riding a bicycle observes that it moves faster on a smooth road than on a rough road. This happens because the smooth road has
(A) less gravity (B) more gravity (C) less friction [correct] (D) more friction
These questions are very difficult to tackle via simple retrieval or word correlations methods.
The Design QA Tasks and Related Datasets
The researchers strongly felt that there is a lack of data in the niche field of difficult science QA tasks. With this in mind the researchers have released a science text corpus and two baseline neural models. The ARC Corpus, contains 14 million science-related sentences with knowledge relevant to ARC but this dataset can easily be used for other tasks. The ARC challenge is carefully designed to avoid scores being heavily dominated by simple systems and algorithms, and hence it encourages research on methods that the more difficult questions demand.
There are numerous datasets available to drive progress in question-answering. Other examples of comprehension datasets are MCTest (Richardson, 2013), SQuAD (Rajpurkar et al., 2016), NewsQA (Trischler et al., 2016), and CNN/DailyMail (Hermann et al., 2015). But these challenges involved answers could be easily found and were “explicitly stated”. TriviaQA (Joshi et al., 2017) made some advancements in this task by providing several articles with a question, and used questions authored independently of the articles. There is a new trend of generating synthetic datasets and the most popular being the bAbI dataset (Weston et al., 2015). Another interesting development was done by the paper, Welbl et al. (2017b) which created the WikiHop dataset. This dataset contained questions that appear to require more than one Wikipedia document to answer (“multihop questions”) and this takes a step towards a more challenging task.
The ARC Dataset
Leading neural models from the SQuAD and SNLI tasks are taken as baseline performance solvers. These neural models are not able to outperform some random models which tells us about the difficulty of the task at hand. To train the models better the researchers release ARC Corpus, a corpus of 14M science sentences relevant to the task, and implementations of the three neural baseline models tested.
The question set is divided into two subparts: challenge set and an easy set. The reason this particular challenge is interesting is because the dataset has grade-school science questions and contains 7,787 questions. Questions vary in their target student grade level, ranging from 3rd grade to 9th. Hence for students typically of age 8 through 13 years. The Challenge Questions are decided by seeing which questions are answered incorrectly by both of two baseline solvers, described above. Although this is a little arbitrary qualification of being a “hard” question, this definition nevertheless serves as a practical and useful filter.
To give a sense of the difficulty of challenge questions, look at this example question:
Which property of air does a barometer measure?
(A) speed (B) pressure [correct] (C) humidity (D) temperature
By using an Information retrieval we get many correct answers:
- Air pressure is measured with a barometer.
- Air pressure will be measured with a barometer.
- The aneroid barometer is an instrument that does not use liquid in measuring the pressure of the air.
- A barometer measures the pressure of air molecules.
The PMI algorithm finds that “barometer” and “pressure” (and also “air” and “pressure”) co-occur unusually frequently (high PMI) in its corpus.
But here is the catch, a better QA system should be able to answer this question:
Which property of a mineral can be determined just by looking at it?
(A) luster [correct] (B) mass (C) weight (D) hardness
This is incorrectly answered by both algorithms whereas we expect a state of the art domain intelligent QA system to understand and answer this question.
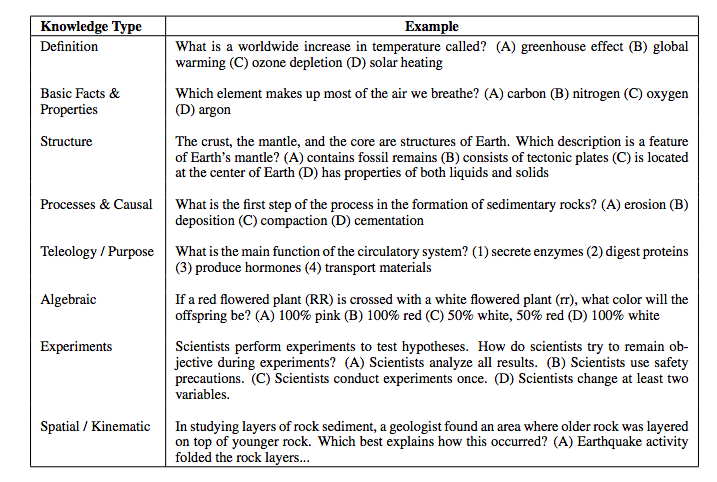
So what do you think, is your AI ready for a challenge?

















