






Data augmentation is often limited to supervised learning, in which labels are required to transfer from original examples to augmented ones. Augmentation provides a steady but limited performance boost. This is because of the fact that they have been applied to a set of labelled examples which is usually of a small size.
To overcome this limitation, Unsupervised Data Augmentation (UDA) has been developed to apply effective data augmentations to unlabeled data, which is often in larger quantities.
In a recent paper titled, Unsupervised Data Augmentation (UDA) for Consistency Training, the authors demonstrate that one can also perform data augmentation on unlabeled data to significantly improve semi-supervised learning (SSL).
Consistency With Data Augmentation

The above picture is an overview of Unsupervised Data Augmentation (UDA). The process from left to right proceeds as follows:
- First, a standard supervised loss is computed when labelled data is available.
- A consistency loss is computed between an example and its augmented version with the help of unlabeled data
The objective of data augmentation is to create a novel training data which resembles reality, by applying a transformation to an example without changing its label.
Unsupervised Data Augmentation (UDA) makes use of both labelled data and unlabeled data and computes the loss function using standard methods for supervised learning to train the model.
To produce the predictions, the above model is applied to the unlabeled example and augmented. This model is applied to both the unlabeled example and its augmented counterpart to produce two model predictions. A consistency loss is then calculated. Here consistency loss should be read as the distance between two prediction distributions.
The final loss computed by UDA is done by jointly optimising both the supervised loss from the labelled data and the unsupervised consistency loss from the unlabeled data.
Setting Benchmarks In NLP And Vision Tasks
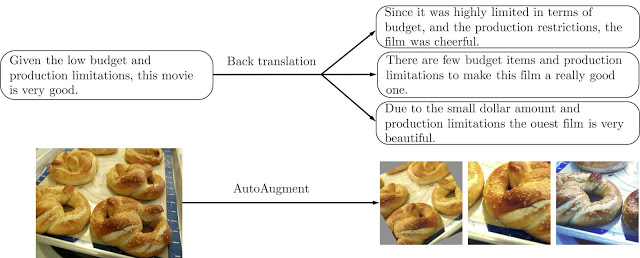
As can be seen in the picture below, an example of text-based and image-based augmentation. Here, the sentence is translated further into more insightful interpretations. Whereas, the image augmented with different orientations.
The following augmentation strategies were used in achieving the above results:
- For image classification, AutoAugment uses reinforcement learning to search for an “optimal” combination of image augmentation operations directly based on the validation performances. The trade-off between diversity and validity is rightly balanced by AutoAugment since it is optimised according to the validation set performances in the supervised setting.
- Back translation to generate diverse paraphrases while preserving the semantics of the original sentences
- TF-IDF based word replacing for Text Classification
To sharpen the predicted distribution produced on unlabeled examples the following three intuitive techniques were employed in the experiments:
- Confidence-based masking
- Entropy minimisation
- Softmax temperature controlling
Experiments are conducted on six language datasets including IMDb, Yelp-2, Yelp-5, Amazon-2, Amazon-5 and DBPedia
The Transformer model used in BERT as baseline model due to its recent success on many tasks. UDA combines well with representation learning, like BERT, and is very effective in a low-data regime where state-of-the-art performance is achieved.
The results in the paper show that UDA is surprisingly effective in the low-data regime. One such experiment done with only 20 labelled examples for sentiment analysis on IMDb yielded in an error rate of 4.20, which outperforms the existing state-of-the-art models.
Key Takeaways
- Semi-Supervised Learning(SSL) can match and even outperform purely supervised learning that uses orders of magnitude more labelled data,
- Various other types of noise have been tested for consistency training (e.g., Gaussian noise, adversarial noise, and others).Data augmentation outperforms all of them.
- SSL combines well with transfer learning, e.g., when fine-tuning from BERT and
- The code is open sourced.


















