



With over 300 million active users monthly, the amount of data that gets generated on Twitter is huge. Handling this torrential data and making sure that the user doesn’t miss out on any important tweets is a challenging job for the data engineers.
Twitter has made many adjustments and tweaked their machine learning algorithms for optimal user experience. To someone in the field of data science, this key takeaway from the article will be the idea how the algorithms are implemented. Non-data science readers will gain an understanding of what’s going behind their screens and why certain tweets show up on their timeline so that they don’t have to grill the CEO demanding the fairness of algorithm for unfair past-time purposes.
Understanding The Algorithm Behind Twitter’s Timeline Ranking
All the tweets since the user’s last visit are gathered and shown in reverse chronological order. Every tweet is given a relevance score by a model. This score indicates the likelihood of the user finding a certain tweet interesting. So, a collection of tweets with higher scores will show up, increasing their visibility. If the number of relevant tweets is high, there again needs to be an order which is now ranked based on the time of posting.
The following factors are considered to make predictions:
- The presence of image or video in the tweet and number of likes
- The user’s past interactions with the one who tweeted
- User’s history of likes and retweets and the time spent on Twitter
A typical user has a habit of refreshing the feed every minute or two. So, this adds up to the already complex scoring model. The model has to calculate the scores and show the tweets in real-time. A good model should have very good quality, should utilise resources at high speed and should offer ease of maintenance.
Checking The Model’s Quality
The first step is to check whether the model is giving high scores to tweets of relevance. A/B tests are run to measure the impact of a tweet on the user; usage and enjoyment being the usual metric here.
A/B tests allow the engineers to verify the accuracy of the model and also to quantify the improvement.
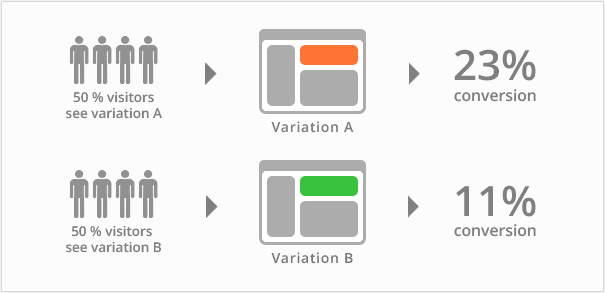
This test is crucial becomes before deploying a model onto the platform. Unless there is a major improvement in user experience, the model doesn’t see the light of the day.
Having the best model is the ultimate goal and it outweighs the reasoning behind the choice of tools and frameworks employed.
A model’s usability and longevity are key factors here. Making a successful model, which cannot be understood by outsiders is short term approach and the development gets hindered.
A Ranking Algorithm That Runs On Deep Learning
With improved architectures and more intuitive understanding of image and natural language understanding, deep learning has found major applications at platforms like Twitter which natively leverage deep learning and complex graphs to meet the ends.
Deep learning models can be composed in various ways (stacked, concatenated, etc.) to form a computational graph. The parameters of this graph can then be learned, typically by using back-propagation and SGD (Stochastic Gradient Descent) on mini-batches.
Libraries like PyTorch make the computational graphs more dynamic and change from one mini-batch to the other.
Tweet ranking belongs to a different domain compared to what the deep learning algorithms are designed for. Due to scattered data and latency requirements, the presence of a feature cannot be guaranteed for each tweet.
Initially, Twitter used algorithms like decision trees for timeline ranking. But for the reasons mentioned above, deep learning was considered to be a suitable candidate to obtain better results on inherently sparse Twitter data.
Twitter’s Cortex team which works on its deep learning platform made few adjustments to ensure that there is a significant improvement in switching to deep learning, using the following techniques:
- To tackle the problem of scattered data and sparse feature values, the team had discretised the input’s sparse features before feeding them to the main deep network.
- A custom sparse linear layer, which has two extra layers:
- Online normalisation scheme to prevent gradient explosion and,
- A per-feature bias to distinguish between the absence of a feature and the presence of a zero-valued feature.
- A custom isotonic calibration layer to explore the space of solution in the training dataset and recalibrate before giving actual probabilities.
- Automatic bundling to retrain and test within Twitter’s clusters for optimal interaction and transparency
- The latency issue is covered by the implementation of optimised modules, which use the right mix of batching, multithreading and hardware utilisation.
All these adjustments paved way for a successful model which is robust and has shown a considerable rise in the number of audiences and their engagement on Twitter.
Looking Forward
To use deep learning as the central modelling for timeline ranking is a smart move by Twitter as this space is constantly improving and the solutions can only get better from here on. With new ideas surfacing every week on how to optimise machine learning algorithms, there is a lot of potential for the machine learning based products to benefit from.













































































