




The recent developments in neural networks have accelerated in a fast pace, so much so that to a beginner it may seem confounding to restrict himself/herself to just one specific area of expertise. As we go forward, researchers try to find ways in which there is a constant improvement in the science of neural networks.
In this article we explore a recent improvement in neural network called ‘synthetic gradients’. This is research coming out of Google’s DeepMind which has a different and interesting take on backpropagation in neural networks. Synthetic gradients have proved to improve communication between multiple neural networks. This is a good sign since it makes the complications involved in deep learning much easier.
Backpropagation: How neural networks learn from data
Neural networks get familiar with data or ‘get trained with data’ using a feedback process called backpropagation. It typically involves comparison of previous outputs with subsequent outputs to observe the difference and then, using that difference to change the weights assigned to make the output error-free as much as possible. The strength of inter-connection between network layers is usually measured in a term called weights. They are usually values assigned to establish a priority among the layers.The weights are manipulated to reduce errors, a process called gradient descent.This way NNs start recognising data and helps them eliminate errors in data along the way.
Neural Networks : The underlying principle
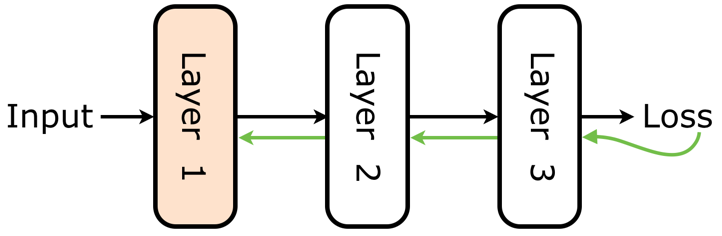
Usually in a neural network, the interaction between individual network layers is restricted to a single direction when it comes to processing the operation sequentially and the output is only relayed after all the layers have executed their operation. For example, consider a NN which has three layers. Once the first input layer processes and passes the data to the second layer, it can only be updated after the output is displayed and all the three layers perform data level executions. This includes error gradients traversing in the opposite direction.
This means that the data is passed from second layer to third layer, and then back propagated to second layer and first input layer in the opposite direction. Until then, the first layer is idle and said to be “locked”. The reason for updating every network layer is to make it familiar with the pattern of data fed into it. This way every layer recognises the familiarity.
Making way for Synthetic gradients in Neural Networks
For a simple network, it may not be a hassle. But, when it comes to large and complex networks, updating instances for each layer is time consuming and pose the threat of clogging data in networks due to delays.
In their study, they begin by decoupling (analogy to the electronics term, decoupling) the network modules (network of NN layers) for multiple machines so that every module is updated independently without relying on other layers for backpropagation. Synthetic gradients use activations at every network layer and present an extra space to use that information for updation. This way data is localised for every layer and the network layers can be updated independently and quickly without much computational complexity. The block diagram presented below will illustrate the concept.

The only setback faced by synthetic gradients is, it needs to be trained prior to its inclusion in NN. For this, backpropagation is again used to obtain error gradients. This makes it an additional task to work on NN. However, the application of the synthetic gradient technique is multifold. In the paper, the application is also extended to Recurrent NN which use computing power efficiently, and also to CNN for image classification.
Conclusion
The application of synthetic gradients for NNs is slowly picking up due to its computing possibilities for quicker and accurate results. In the end it’s up to the user to experiment and come up with useful methods to implement in any NN architecture, which has its own set of challenges and benefits. The avenue for research is definitely fruitful in NN.

















