



Last year, researchers at Google applied the “cocktail party effect” observed by human beings to machines. For instance, in a party, there are so many voices, but we only listen to the person we like by focusing our mind on that face.
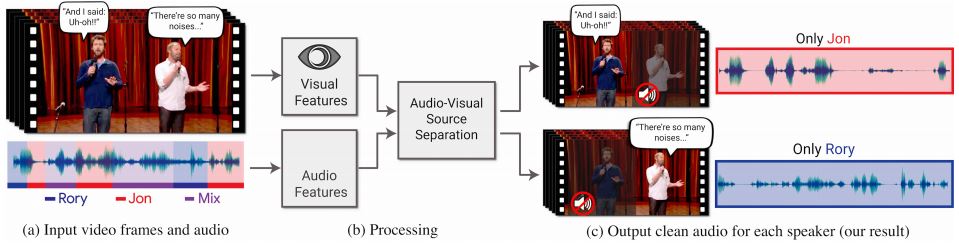
We all know the idea of speech separation is not new. Few years ago, work on speech-separation and audio-visual signal processing was already accomplished by researchers using neural network model. But there were some limitations in these models such as they are speaker-dependent where a dedicated model must be trained for each speaker separately which limit their applicability. To overcome this speaker-dependency, last year, the researchers at Google came up with this new deep-net based model to address the problem of speaker-independent AV speech separation.
The Audio-Visual Speech Separation Model
The interesting fact about the research is that the focus of the researchers was not only on the speech but also on the visual cues, for instance, the subject’s lip movements including other facial movements that results to what he/she is saying. The visual cues are used to focus the audio on a particular subject who is speaking, thus improving the quality of speech separation.
A collection of 100,000 high-quality videos of lectures, how-to videos and TED-talks have been collected from YouTube to generate training examples. These videos help in extracting clean speech without any extra sound like music, audience running in the background. This clean data known as AVSpeech is then used to generate a training set of “synthetic cocktail parties” by mixing face videos and their corresponding speech from separate video sources along with non-speech background noise from Google’s AudioSet.
Researchers developed a multi-stream convolution neural network-based model by using this data in order to split the synthetic cocktail mixture into separate audio streams for each individual speaker in the video.
The Model Architecture

The input for this network were visual features extracted from the face thumbnails of detected speakers in each frame. For training the model, the network learns to separate the visual as well as the auditory signals. After separating, it fuses them together to build a joint audio-visual representation which helps the network to learn to output a time-frequency mask for each speaker. These output masks are multiplied by the noisy input spectrogram which describes the time-frequency relationships of clean speech to background inference.
Use Cases
There are multiple instances where the CNN model has been implied such as given below
- Video conferencing (Click here to watch the video)
- Sports debate (Click here to watch the video)
- Noisy Cafeteria (Click here to watch the video)
Advantages
This method for isolating single speech in a noisy environment helps in various ways such as
- Speech enhancement and recognition in videos
- Enhancement in video conferencing
- Improving hearing aids
- Speech separation in the wild where there are multiple people speaking, or undisputed video, etc.

















































































