




At Cloud Next’19, an ongoing event at San Francisco, Google launched its very own AI platform. This platform aims at making the life of machine learning developers, data scientists and data engineers easy.

This AI Platform supports Kubeflow, Google’s open-source platform, which lets the users build portable ML pipelines that can be run on-premises or on Google Cloud without significant code changes. And, Kubeflow, AI Hub, and notebooks can be used for no charge.
“So you can start with exploratory data analysis, start to build models using a data scientist, decide you want to use a specific model, and then essentially with one click be able to deploy it in our Google Cloud or in other clouds, or on-premises running on top of Kubernetes,” said Google Cloud chief AI scientist Andrew Moore on the eve of Cloud Next’19 event.
Along with the announcement of its AI platform, Google also made the following announcements:
- AutoML updates—including AutoML Tables (beta), AutoML Video Intelligence (beta), AutoML Vision Edge (beta) and object detection (beta), and AutoML Natural Language custom entity extraction (beta)—offer developers with minimal ML expertise more ways to train and deploy high-quality custom machine learning models.
- Document Understanding AI, in beta, offers a scalable, serverless platform to automatically classify, extract, and digitize data within your scanned or digital documents.
- Contact Center AI is now in beta, helping businesses build modern, intuitive customer care experiences with the help of Google AI.
- Retail-oriented solutions, including Vision Product Search (GA) and Recommendations AI (beta), help retailers take advantage of AI for their unique business cases.
End-to-end ML Pipeline with AI Platform
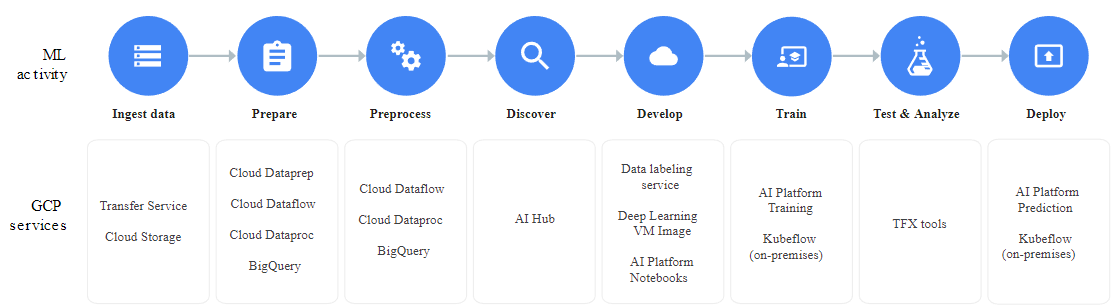
Google’s cloud storage or BigQuery to store data while building data labeling service for training. And, then import the labeled data to AutoML to train the model directly.
Once the training is done, users can run their deep learning models via Google Cloud Platform in a serverless environment or using microservices provided by Kubeflow.
AI Platform runs the training in the cloud. Train can be done with a built-in algorithm (beta)on the dataset without writing a training application. If built-in algorithms do not fit the use case, a training application can be created to run on AI Platform.
The AI Platform training service is designed to have as little impact on the application as possible.
The data in the training job must obey the following rules to run on AI Platform:
- The data must be in a format that can be read and fed to TensorFlow code.
- The data must be in a location that code can access.Which means it should be stored with one of the GCP storage or big data services.
The Kubeflow pipelines enables model management and end-to-end work flows control. These pipelines can be leveraged to build reusable end-to-end ML pipelines.
The AI Platform training service doesn’t provide any special interface for working with GPUs. The user can specify GPU-enabled machines to run the job, and the service allocates it.

With domain expertise from partners like Intel, Cisco and Nvidia, GCP aims to democratise the use of ML on a large scale.
Check more about the AI Platform here















































































