


Every decade seems to have its technological buzzwords: we had personal computers in 1980s; Internet and worldwide web in 1990s; smart phones and social media in 2000s; and Artificial Intelligence (AI) and Machine Learning in this decade. However, the field of AI is 67 years old and this is the first of a series of five articles wherein:
- This article discusses the genesis of AI and the first hype cycle during 1950 and 1982
- The second article discusses a resurgence of AI and its achievements during 1983-2010
- The third article discusses the domains in which AI systems are already rivaling Humans
- The fourth article discusses the current hype cycle in Artificial Intelligence
- The fifth article discusses as to what 2018-2035 may portend for brains, minds and machines

Introduction
While artificial intelligence (AI) is among today’s most popular topics, a commonly forgotten fact is that it was actually born in 1950 and went through a hype cycle between 1956 and 1982. The purpose of this article is to highlight some of the achievements that took place during the boom phase of this cycle and explain what led to its bust phase. The lessons to be learned from this hype cycle should not be overlooked – its successes formed the archetypes for machine learning algorithms used today, and its shortcomings indicated the dangers of overenthusiasm in promising fields of research and development.
The Pioneering Question
Although the first computers were developed during World War II [1,2], what seemed to truly spark the field of AI was a question proposed by Alan Turing in 1950 [3]: can a machine imitate human intelligence? In his seminal paper, “Computing Machinery and Intelligence,” he formulated a game, called the imitation game, in which a human, a computer, and a (human) interrogator are in three different rooms. The interrogator’s goal is to distinguish the human from the computer by asking them a series of questions and reading their typewritten responses; the computer’s goal is to convince the interrogator that it is the human [3]. In a 1952 BBC interview, Turing suggested that, by the year 2000, the average interrogator would have less than a 70% chance of correctly identifying the human after a five-minute session [4].
 Figure 1: The imitation game, as proposed by Alan Turing
Figure 1: The imitation game, as proposed by Alan Turing
Turing was not the only one to ask whether a machine could model intelligent life. In 1951, Marvin Minsky, a graduate student inspired by earlier neuroscience research indicating that the brain was composed of an electrical network of neurons firing with all-or-nothing pulses, attempted to computationally model the behavior of a rat. In collaboration with physics graduate student Dean Edmonds, he built the first neural network machine called Stochastic Neural Analogy Reinforcement Computer (SNARC) [5]. Although primitive (consisting of about 300 vacuum tubes and motors), it was successful in modeling the behavior of a rat in a small maze searching for food [5].
The notion that it might be possible to create an intelligent machine was an alluring one indeed, and it led to several subsequent developments. For instance, Arthur Samuel built a Checkers-playing program in 1952 that was the world’s first self-learning program [14]. Later, in 1955, Newell, Simon and Shaw built Logic Theorist, which was the first program to mimic the problem-solving skills of a human and would eventually prove 38 of the first 52 theorems in Whitehead and Russell’s Principia Mathematica [6].
 Figure 2: Picture of a single neuron contained in SNARC (Source: Gregory Loan, 1950s)
Figure 2: Picture of a single neuron contained in SNARC (Source: Gregory Loan, 1950s)
The Beginning of the Boom Phase
Inspired by these successes, young Dartmouth professor John McCarthy organized a conference in 1956 to gather twenty pioneering researchers and, “explore ways to make a machine that could reason like a human, was capable of abstract thought, problem-solving and self-improvement” [7]. It was in his 1955 proposal for this conference where the term, “artificial intelligence,” was coined, and it was at this conference where AI gained its vision, mission, and hype.
Researchers soon began making audacious claims about the incipience of powerful machine intelligence, and many anticipated that a machine as intelligent as a human would exist in no more than a generation [40,41,42]. For instance:
- In 1958, Simon and Newell said, “within ten years a digital computer will be the world’s chess champion,” and, “within ten years a digital computer will discover and prove an important new mathematical theorem” [8].
- In 1961, Minsky wrote, “within our lifetime machines may surpass us in general intelligence,” [9] and in 1967 he reiterated, “within a generation, I am convinced, few compartments of intellect will remain outside the machine’s realm – the problem of creating ‘artificial intelligence’ will be substantially solved” [10, 11, 12].
AI had even caught Hollywood’s attention. In 1968, Arthur Clarke and Stanley Kubrick produced the movie, 2001: A Space Odyssey, whose antagonist was an artificially intelligent computer, HAL 9000 exhibiting creativity, a sense of humor, and the ability to scheme against anyone who threatened its survival. This was based on the belief held by Turing, Minsky, McCarthy and many others that such a machine would exist by 2000; in fact, Minsky served as an adviser for this film and one of its characters, Victor Kaminski, was named in his honor.
 Figure 3: HAL 9000, as shown in 2001: A Space Odyssey
Figure 3: HAL 9000, as shown in 2001: A Space Odyssey
We should add in the bottom of the red ball: “This sort of thing has cropped up before, and it has always been due to human error”
Subfields of AI are Born
Between 1956 and 1982, the unabated enthusiasm in AI led to seminal work, which gave birth to several subfields of AI that are explained below. Much of this work led to the first prototypes for the modern theory of AI.
 Figure 4: Important subfields of AI as of 1982
Figure 4: Important subfields of AI as of 1982
Rules Based Systems: Rule based expert systems try to solve complex problems by implementing series of “if-then-else” rules. One advantage to such systems is that their instructions (what the program should do when it sees “if” or “else”) are flexible and can be modified either by the coder, user or program itself. Such expert systems were created and used in the 1970s by Feigenbaum and his colleagues [13], and many of them constitute the foundation blocks for AI systems today.
Machine Learning: The field of machine learning was coined by Arthur Samuel in 1959 as, “the field of study that gives computers the ability to learn without being explicitly programmed” [14]. Machine learning is a vast field and its detailed explanation is beyond the scope of this article. The second article in this series – see Prologue on the first page and [57] – will briefly discuss its subfields and applications. However, below we give one example of a machine learning program, known as the perceptron network.
Single and Multilayer Perceptron Networks: Inspired by the work of McCulloch and Pitts in 1943 and of Hebb in 1949, Rosenblatt in 1957 introduced the perceptron network as an artificial model of communicating neurons. This model is shown in Figure 5 and can be briefly described as follows. One layer of vertices, where input variables are entered, is connected to a hidden layer of vertices (also called perceptrons), which in turn is connected to an output layer of perceptrons. A signal coming via a connection from an input vertex to a perceptron in the hidden layer is calibrated by a “weight” associated with that connection, and this weight is assigned during a “learning process”. Signals from hidden layer perceptrons to output layer perceptrons are calibrated in an analogous way. Like a human neuron, a perceptron “fires” if the total weight of all incoming signals exceeds a specified potential. However, unlike for humans, signals in this model are only transmitted towards the output layer, which is why these networks are often called “feed-forward.” Perceptron networks with only one hidden layer of perceptrons (i.e., with two layers of weighted edge connections) later became known as “shallow” artificial neural networks. Although shallow networks were limited in power, Rosenblatt managed to create a one-layer perceptron network, which he called created Mark 1, that was able to recognize basic images.
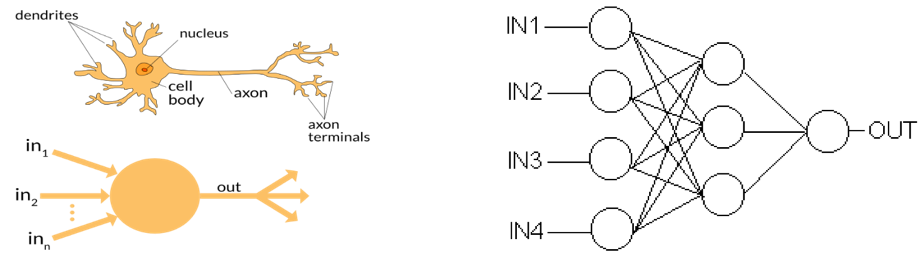 Figure 5: A human neuron versus a perceptron A shallow perceptron network
Figure 5: A human neuron versus a perceptron A shallow perceptron network
Today, the excitement is about “deep” (two or more hidden layers) neural networks, which were also studied in the 1960s. Indeed, the first general learning algorithm for deep networks goes back to the work of Ivakhnenko and Lapa in 1965 [18,19]. Networks as deep as eight layers were considered by Ivakhnenko in 1971, when he also provided a technique for training them [20].
Natural Language Processing (NLP): In 1957 Chomsky revolutionized linguistics with universal grammar, a rule based system for understanding syntax [21]. This formed the first model that researchers could use to create successful NLP systems in the 1960s, including SHRDLU, a program which worked with small vocabularies and was partially able to understand textual documents in specific domains [22]. During the early 1970s, researchers started writing conceptual ontologies, which are data structures that allow computers to interpret relationships between words, phrases and concepts; these ontologies widely remain in use today [23].
Speaker Recognition and Speech to Text Processing: The question of whether a computer could recognize speech was first proposed by three researchers at AT&T Bell Labs in 1952, when they built a system for isolated digit recognition for a single speaker [24]. This system was vastly improved during the late 1960s, when Reddy created the Hearsay I, a program which had low accuracy but was one of the first to convert large vocabulary continuous speech into text. In 1975, his students Baker and Baker created the Dragon System [25], which further improved upon Hearsay I by using the Hidden Markov Model (HMM), a unified probabilistic model that allowed them to combine various sources such as acoustics, language, and syntax. Today, the HMM remains an effective framework for speech recognition [26].
Image Processing and Computer Vision: In the summer of 1966, Minsky hired a first-year undergraduate student at MIT and asked him to solve the following problem: connect a television camera to a computer and get the machine to describe what it sees [27]. The aim was to extract three-dimensional structure from images, thereby enabling robotic sensory systems to partially mimic the human visual system. Research in computer vision in the early 1970s formed the foundation for many algorithms that exist today, including extracting edges from images, labeling lines and circles, and estimating motion in videos [28].
Commercial Applications
The above theoretical advances led to several applications, most of which fell short of being used in practice at that time but set the stage for their derivatives to be used commercially later. Some of these applications are discussed below.
Chatterbots or Chat-Bots: Between 1964 and 1966, Weizenbaum created the first chat-bot, ELIZA, named after Eliza Doolittle who was taught to speak properly in Bernard Shaw’s novel, Pygmalion (later adapted into the movie, My Fair Lady). ELIZA could carry out conversations that would sometimes fool users into believing that they were communicating with a human but, as it happens, ELIZA only gave standard responses that were often meaningless [29]. Later in 1972, medical researcher Colby created a “paranoid” chatbot, PARRY, which was also a mindless program. Still, in short imitation games, psychiatrists were unable to distinguish PARRY’s ramblings from those of a paranoid human’s [30].
 Figure 6: Conversations with Weizenbaum’s ELIZA and Colby’s PARRY
Figure 6: Conversations with Weizenbaum’s ELIZA and Colby’s PARRY
Robotics: In 1954, Devol built the first programmable robot called, Unimate, which was one of the few AI inventions of its time to be commercialized; it was bought by General Motors in 1961 for use in automobile assembly lines [31]. Significantly improving on Unimate, researchers at Waseda University in 1972 built the world’s first full-scale intelligent humanoid robot, WABOT-1 [32]. Although it was almost a toy, its limb system allowed it to walk and grip as well as transport objects with hands; its vision system (consisting of its artificial eyes and ears) allowed it to measure distances and directions to objects; and its artificial mouth allowed it to converse in Japanese [32]. This gradually led to innovative work in machine vision, including the creation of robots that could stack blocks [33].
 Figure 7: Timeline of important inventions in AI between 1950-75
Figure 7: Timeline of important inventions in AI between 1950-75
The Bust Phase and the AI Winter
Despite some successes, by 1975 AI programs were largely limited to solving rudimentary problems. In hindsight, researchers realized two fundamental issues with their approach.
Limited and Costly Computing Power: In 1976, the world’s fastest supercomputer (which would have cost over five million US Dollars) was only capable of performing about 100 million instructions per second [34]. In contrast, the 1976 study by Moravec indicated that even the edge-matching and motion detection capabilities alone of a human retina would require a computer to execute such instructions ten times faster [35]. Likewise, a human has about 86 billion neurons and one trillion synapses; basic computations using the figures provided in [36,37] indicate that creating a perceptron network of that size would have cost over 1.6 trillion USD, consuming the entire U.S. GDP in 1974.
The Mystery Behind Human Thought: Scientists did not understand how the human brain functions and remained especially unaware of the neurological mechanisms behind creativity, reasoning and humor. The lack of an understanding as to what precisely machine learning programs should be trying to imitate posed a significant obstacle to moving the theory of artificial intelligence forward. In fact, in the 1970s, scientists in other fields even began to question the notion of, “imitating a human brain,” proposed by AI researchers. For example, some argued that if symbols have no “meaning” for the machine, then the machine could not be described as “thinking” [38].
Eventually, it became obvious to the pioneers that they had grossly underestimated the difficulty of creating an AI computer capable of winning the imitation game. For example, in 1969, Minsky and Papert published the book, Perceptrons [39], in which they indicated severe limitations of Rosenblatt’s one-hidden layer perceptron. Coauthored by one of the founders of artificial intelligence while attesting to the shortcomings of perceptrons, this book served as a serious deterrent towards research in neural networks for almost a decade [40,41,42].
In the following years, other researchers began to share Minsky’s doubts in the incipient future of strong AI. For example, in a 1977 conference, a now much more circumspect John McCarthy noted that creating such a machine would require “conceptual breakthroughs,” because “what you want is 1.7 Einsteins and 0.3 of the Manhattan Project, and you want the Einsteins first. I believe it’ll take five to 500 years” [43].
The hype of the 1950s had raised expectations to such audacious heights that, when the results did not materialize by 1973, the U.S. and British governments withdrew research funding in AI [41, page 117; 41, page 22]. Although the Japanese government temporarily provided additional funding in 1980, it quickly became disillusioned by the late 1980s and withdrew its investments again [42, page 441; 40, page 212]. This bust phase (particularly between 1974 and 1982) is commonly referred to as the “AI winter,” as it was when research in artificial intelligence almost stopped completely. Indeed, during this time and the subsequent years, “some computer scientists and software engineers would avoid the term artificial intelligence for fear of being viewed as wild-eyed dreamers” [44].
The prevailing attitude during the 1974-1982 period was highly unfortunate, as the few substantial advances that took place during this period essentially went unnoticed, and significant effort was undertaken to recreate them. Two such advances are the following:
- The first is the backpropagation technique, which is commonly used today to efficiently train neural networks in assigning near-optimal weights to their edges. Although it was introduced by several researchers independently (e.g., Kelley, Bryson, Dreyfus, and Ho) in 1960s [45] and implemented by Linnainmaa in 1970 [46], it was mainly ignored. Similarly, the 1974 thesis of Werbos that proposed that this technique could be used effectively for training neural networks was not published until 1982, when the bust phase was nearing its end [47,48]. In 1986, this technique was rediscovered by Rumelhart, Hinton and Williams, who popularized it by showing its practical significance [49].
- The second is the recurrent neural network (RNN), which is analogous to Rosenblatt’s perceptron network that is not feed-forward because it allows connections to go towards both the input and output layers. Such networks were proposed by Little in 1974 as a more biologically accurate model of the brain. Regrettably, RNNs went unnoticed until Hopfield popularized them in 1982 and improved them further [50,51].
Conclusion
The defining characteristics of a hype cycle are a boom phase, when researchers, developers and investors become overly optimistic and enormous growth takes place, and a bust phase, when investments are withdrawn, and growth reduces substantially. From the story presented in this article, we can see that AI went through such a cycle during 1956 and 1982.
Born from the vision of Turing and Minsky that a machine could imitate intelligent life, AI received its name, mission, and hype from the conference organized by McCarthy at Dartmouth University in 1956. This marked the beginning of the boom phase of the AI hype cycle. Between 1956 and 1973, many penetrating theoretical and practical advances were discovered in the field of AI, including rule-based systems; shallow and deep neural networks; natural language processing; speech processing; and image recognition. The achievements that took place during this time formed the initial archetypes for current AI systems.
What also took place during this boom phase was “irrational exuberance” [52]. The pioneers of AI were quick to make exaggerated predictions about the future of strong artificially intelligent machines. By 1974, these predictions did not come to pass, and researchers realized that their promises had been inflated. By this point, investors had also become skeptical and withdrew funding. This resulted in a bust phase, also called the AI winter, when research in AI was slow and even the term, “artificial intelligence,” was spurned. Most of the few inventions during this period, such as backpropagation and recurrent neural networks, went largely overlooked, and substantial effort was spent to rediscover them in the subsequent decades.
In general hype cycles are double-ended swords, and the one exhibited by AI between 1956 and 1982 was no different. Care must be taken to learn from it: the successes of its boom phase should be remembered and appreciated, but its overenthusiasm should be viewed with at least some skepticism to avoid the full penalties of the bust phase. However, like most hype cycles, “green shoots” start appearing again in mid 1980s and there was a gradual resurgence of AI research during 1983 and 2010; we will discuss these and related developments in our next article, “Resurgence of Artificial Intelligence During 1983-2010” [57].
References: The bibliography for all five articles can be found at www.scryanalytics.com/articles.



































































































