Data scientists come across many datasets and not all of them may be well formatted or noise free. While doing any kind of analysis with data it is important to clean it, as raw data can be highly unstructured with noise or missing data or data that is varying in scales which makes it hard to extract useful information. Data Preprocessing is the process of preparing the data for analysis. This is the first step in any machine learning model.
Here in this simple tutorial we will learn to implement Data preprocessing to perform the following operations on a raw dataset:
- Dealing with missing data
- Dealing with categorical data
- Splitting the dataset into training and testing sets
- Scaling the features
Data Preprocessing in Python
Following this tutorial will require you to have:
- Basic programming knowledge in python
Let’s start coding:
Importing the pandas
import pandas as pd
Loading the dataset
dataset = pd.read_excel("age_salary.xls")
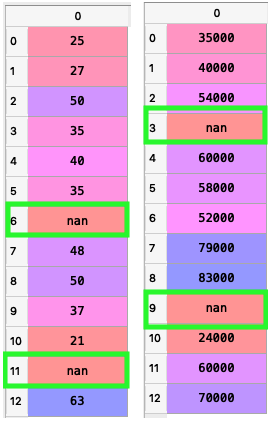
The data set used here is as simple as shown below:

Note:
The ‘nan’ you see in some cells of the dataframe denotes the missing fields
Now that we have loaded our dataset lets play with it.
Classifying the dependent and Independent Variables
Having seen the data we can clearly identify the dependent and independent factors.Here we just have 2 factors, age and salary.Salary is the dependent factor that changes with the independent factor age.Now let’s classify them programmatically.
X = dataset.iloc[:,:-1].values #Takes all rows of all columns except the last column
Y = dataset.iloc[:,-1].values # Takes all rows of the last column
- X : independent variable set
- Y : dependent variable set
The dependent and independent values are stored in different arrays. In case of multiple independent variables use X = dataset.iloc[:,a:b].values where a is the starting range and b is the ending range (column indices). You can also specify the column indices in a list to select specific columns.
Dealing with Missing Data
We have already noticed the missing fields in the data denoted by “nan”. Machine learning models cannot accommodate missing fields in the data they are provided with.So the missing fields must be filled with values that will not affect the variance of the data or make it more noisy.
from sklearn.impute import SimpleImputer
imp = SimpleImputer(missing_values=np.nan, strategy="mean")
X = imp.fit_transform(X)
Y = Y.reshape(-1,1)
Y = imp.fit_transform(Y)
Y = Y.reshape(-1)
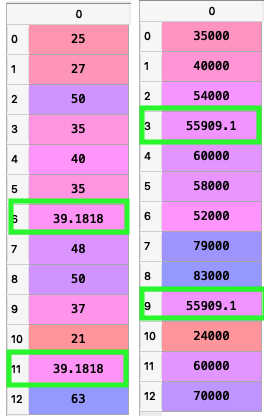
The scikit-learn library’s SimpleImputer Class allows us to impute the missing fields in a dataset with valid data. In the above code, we have used the default strategy for filling missing values which is the mean. The imputer can not be applied on 1D arrays and since Y is a 1D array, it needs to be converted to a compatible shape.The reshape functions allows us to reshape any array.The fit_transform() method will fit the imputer object and then transforms the arrays.
Output
Dealing with Categorical Data
When dealing with large and real-world datasets, categorical data is almost inevitable.Categorical variables represent types of data which may be divided into groups. Examples of categorical variables are race, sex, age group, educational level etc. These variables often has letters or words as its values. Since machine learning models are all about numbers and calculations , these categorical variables need to be coded in to numbers. Having coded the categorical variable into numbers may just not be enough.
For example, consider the dataset below with 2 categorical features nation and purchased_item. Let us assume that the dataset is a record of how age, salary and country of a person determine if an item is purchased or not.Thus purchased_item is the dependent factor and age, salary and nation are the independent factors.
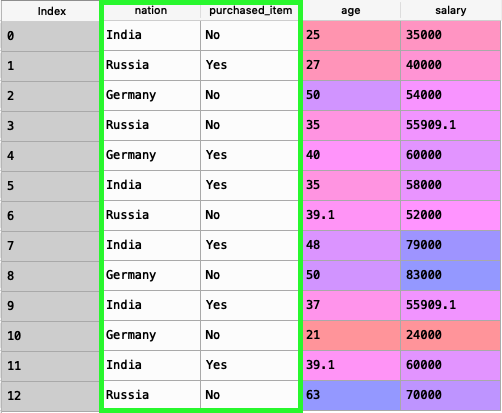
It has 3 countries listed. In a larger dataset, these may be large groups of data. Since countries don’t have a mathematical relation between them unless we are considering some known factors such as size or population etc , coding them in numbers will not work, as a number may be less than or greater than another number. Dummy variables are the solution. Using one hot encoding we will create a dummy variable for each of the category in the column. And uses binary encoding for each dummy variable. We do not need to create dummy variables for the feature purchased_item as it has only 2 categories either yes or no.
dataset = pd.read_csv("dataset.csv")
X = dataset.iloc[:,[0,2,3]].values
Y = dataset.iloc[:,1].values
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
le_X = LabelEncoder()
X[:,0] = le_X.fit_transform(X[:,0])
ohe_X = OneHotEncoder(categorical_features = [0])
X = ohe_X.fit_transform(X).toarray()
Output

The the first 3 columns are the dummy features representing Germany,India and Russia respectively.The 1’s in each column represent that the person belongs to that specific country.
Y = le_X.fit_transform(Y)
Output:
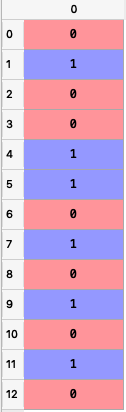
Splitting the Dataset into Training and Testing sets
All machine learning models require us to provide a training set for the machine so that the model can train from that data to understand the relations between features and can predict for new observations.When we are provided a single huge dataset with too much of observations ,it is a good idea to split the dataset into to two, a training_set and a test_set, so that we can test our model after its been trained with the training_set.
Scikit-learn comes with a method called train_test_split to help us with this task.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.3, random_state = 0)
The above code will split X and Y into two subsets each.
- test_size: the desired size of the test_set. 0.3 denotes 30%.
- random_state: This is used to preserve the uniqueness. The split will happen uniquely for a random_state.
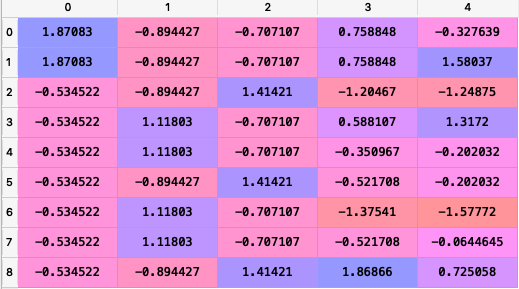
Scaling the features
Since machine learning models rely on numbers to solve relations it is important to have similarly scaled data in a dataset. Scaling ensures that all data in a dataset falls in the same range.Unscaled data can cause inaccurate or false predictions.Some machine learning algorithms can handle feature scaling on its own and doesn’t require it explicitly.
The StandardScaler class from the scikit-learn library can help us scale the dataset.
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)
sc_y = StandardScaler()
Y_train = Y_train.reshape((len(Y_train), 1))
Y_train = sc_y.fit_transform(Y_train)
Y_train = Y_train.ravel()
Output
X_train before scaling :

X_train after scaling :