



In a previous article it was seen that corporate data can be divided into distinct sectors. Fig 1 depicts the different sectors into which corporate data can be divided.
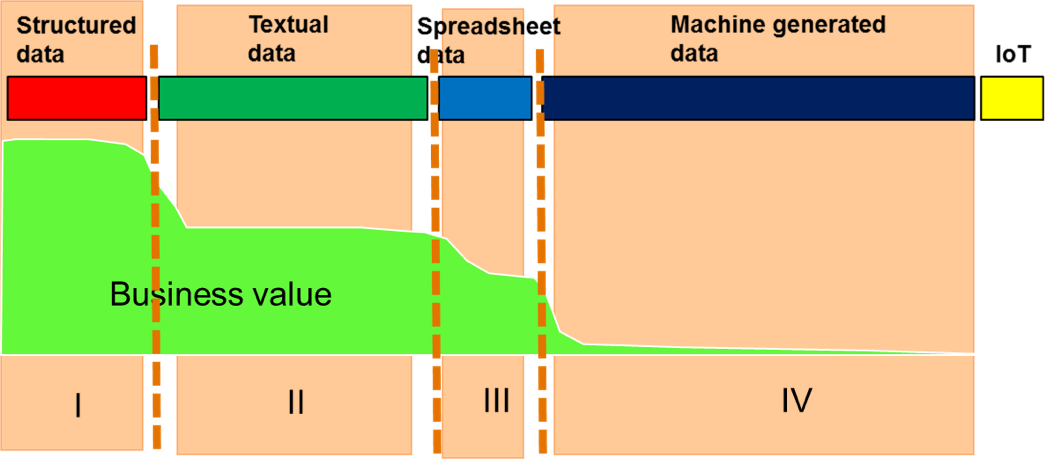
The sectors are –
- Structured data
- Textual data
- Spreadsheet data
- Machine generated data
Each of these sectors have their own characteristics and idiosyncrasies.
STRUCTURED DATA
Structured data is the sector that has been around the longest. It was the sector on which most technology is based. Modern data base management systems are built to accommodate data found in this sector. There are typically many records which – structurally – have the same identical structure. This uniformity of structure is where the name – “structured data” – comes from.
Most analytical processing has its origins in structured data. Typical technology such as Tableau, Qlik, Microstrategy, Business Objects, and so forth all have their origin in this sector.
Data science does address – to a lesser extent – this sector.
There is a lot of business value to be found in this sector. That is because much of the data found in this sector is directly tied to the transactions conducted by the business. The business value found here is both operational and strategic.
Fig 2 shows this sector

TEXTUAL DATA
If there is any sector of data that is unexplored it is the textual sector of data. There is much business value in this sector. But the business value is almost untouched. There are lots of reasons why textual data is almost untouched –
Text does not fit nicely and naturally into standard technology such as a data base management system,
Text is inherently complex. There are many nuances of text that are hard to capture in a standard computer. The human brain has built into it many background rules for processing language. Unfortunately many of these rules are complex and are not intuitive. But because these rules are learned from birth, they are taken for granted. However once language is inside the computer, the computer must be “taught” many of these rules.
There have been technological advances which have been able to start to cope with language and text. However the technology needed to deal with text is not nearly as developed and as mature as the technology required to deal with structured data.
Data science has hardly touched the world of text, and this is a shame because there is GREAT business opportunity there that has not been tapped.
From the standpoint of opportunity this sector of data is the most promising.
Fig 3 shows this sector –

SPREADSHEET DATA
Like the textual data sector there is great untapped opportunity in the spreadsheet sector. And like the textual sector, there has hardly been any activity that attempts to tap the spreadsheet sector.
Spreadsheets are used in (at least!) two ways – as a mechanism that allows the end user autonomy to create and manage his/her own data and as a means for communication between organizations. In the case of a means of communication, one organization sends a spreadsheet to another corporation and hopes the corporation that receives it is able to understand the contents of the spreadsheet.
The reason why spreadsheets are not widely used for management decisions based on the spreadsheet is the unreliability of the data found on the spreadsheet.
Nevertheless there is great potential for business value to be discovered in spreadsheets. And like textual information, the business value is hardly tapped.
Fig 4 depicts this sector –
MACHINE GENERATED DATA
Machines are capable of generating data at a terrific rate. Satellites can send down data scanned from the heavens at a huge rate. Electric eyes can scan objects on a conveyer belt at a very fast pace. Manufacturing machines can measure, scan, and weigh produce very rapidly. In a word data can be produced by machines at a rate that easily surpasses what mere humans can do.
And data scientists have a fixation on looking at this data.
The data produced by machines tends to be very uniform – very structurally homogenous. The data produced by machines lends itself to the statistical analysis techniques favored by data scientists.
The problems is – for a variety of reasons – there isn’t much business value to be found. Or what business value there is to be found there is operational business value, not strategic business value.
Fig 5 shows this sector of corporate data –

Each of the sectors of corporate data has their own characteristics, in terms of –
Maturity
Business value
Attention from the data scientist
Volume of data
And so forth






































































