



With computer vision gaining ground in business applications, advanced computer vision methods are gaining strides in a range of industries — from healthcare to medical imaging and automotive sector. While it is widely leveraged for self-driving cars, face recognition applications and object detection, one of the most difficult parts of computer vision is object counting.
This is also an important task in computer vision and has many applications in traffic monitoring, surveillance and counting everyday objects. The present method for object counting using regression-based optimization is a straightforward method to count objects. According to researchers, a regression-based optimization method fares better than detection-based methods.
The researchers at Element AI and University of British Columbia have built a detection based method that does not work on estimating the size and shape of the objects. This algorithm outperforms regression-based methods. The researchers say that their contributions have three major outcomes:
- The researchers built a novel loss function that encourages the network to output a single blob per object instance using pointlevel annotations only;
(2) The researchers have built two methods for splitting large predicted blobs between object instances;
(3) The researchers show that their method achieves new state-of-the-art results on several challenging datasets including the Pascal VOC and the Penguins dataset.
In addition to the above, the research also proved that their methods have outperformed methods that depend upon supervision such as bounding-box labels, depth features and multi-point annotations
Detection Based Methods For Counting
In many important computer vision application such in traffic monitoring, counting is an important component of the whole workflow. They are used used to track the number of moving cars, parked cars, other vehicles and pedestrians. Besides traffic monitoring, computer-vision powered object counting can also play a role in mapping of different species. For example, when fed with large amount of image data, these algorithms can be used to monitor the count of different species such as penguins and aid in conservation. It is very important for models to learn the variability of the objects in terms of pose, shape, size, and appearance to do well in counting tasks.
Regression based methods worked well because their loss functions are designed to count objects. As opposed to this, detection-based methods work on a more difficult task such as estimating the shape, location and size of the object instances.Because of this difficulty detection based models often lead to bad results for object counting. For this reason, researchers work to sidestep the problem and look to focusing on the task of simply localizing object instances in the scene.

However, figuring out the shape and size of the object is very difficult and not necessary to solve. So they designed a new loss function that according to researchers, “encourages the model to output instance regions such that each region contains a single object instance (i.e. a single point-level annotation).”
Localization-based Counting FCN
The researchers have given only point-level annotations and this model:
(a) enforces it to predict the semantic segmentation labels for each pixel in the image, and
(b) encourages it to output a segmentation blob for each object instance.
The blobs have more than one point annotation and to remove the blobs that contain no point-level annotations, the experiments done by researchers show that their recent methods achieve better results compared to state-of-the-art counting methods.
The researchers used counting results for the PASCAL VOC dataset. This datasets also consists of objects present in everyday world. Some of the benchmarks used by researchers for object counting are: Mall, UCSD for crowd datasets; MIT Traffic for surveillance datasets and Penguins as a population monitoring dataset.
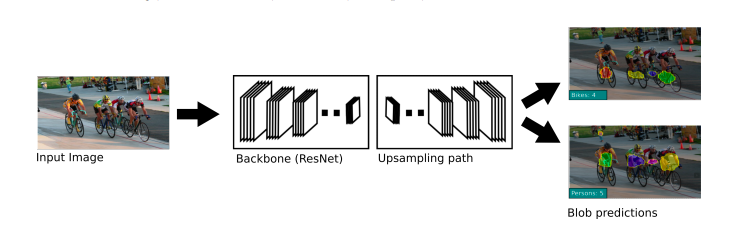
The model built by researchers from Element AI and University of British Columbia is one of the best localization based algorithms in computer vision. The researcher have designed a model based on the fully convolutional neural network (FCN). Researchers are successful in extending the semantic segmentation loss component of the architecture to do the object counting and localization. They denote the novel loss function as localization-based counting loss (LC) and the new architecture is called as LC-FCN.
Proposed Loss Function
Now, LC-FCN built by researchers uses four distinct components. As the researchers state, “The first two terms, the image-level and the point-level loss enforces the model to predict the semantic segmentation labels for each pixel in the image.The last two terms encourage the model to output a unique blob for each object instance and remove blobs that have no object instances. Note that LC-FCN only requires point-level annotations that indicate the locations of the objects rather than their sizes, and shapes.”
The last two components of the loss function help to output a unique blog for each object in the model and remove blobs that are not attached to any objects. The researchers highlight that LC-FCN requires point-level annotations that indicate the locations of the objects and they do not require their sizes, and shapes.
The methods put forward by researchers significantly outperform other methods on the Penguin dataset even though other methods use depth features and the multiple annotations. LC-FCN proposed by the researchers significantly outperforms Glance in counting cars in the parking lot among many other tasks. The researchers concluded that, “Experimental results show that LC-FCN outperforms current state of-the-art models on the PASCAL VOC 2007, Trancos, and Penguins datasets which contain objects that are heavily occluded. For future work, we plan to explore different FCN architectures and splitting methods that LC-FCN can use to efficiently split between overlapping objects that have complicated shapes and appearances”















































































