



Machine learning is a field that has emerged out of numerous innovations in computational sciences, spanning centuries. So, can a machine learning enthusiast skip linear algebra and flourish? The short answer is — NO.
However, that’s not a complete picture.
Linear Algebra is a branch of mathematics that is widely used throughout science and engineering. Good understanding of linear algebra is essential for understanding and working with many ML algorithms, especially deep learning algorithms.
To understand this better, we are listing down the areas where an ML enthusiast will run into linear algebra in the preliminary stages of machine learning:
Scalars, Vectors, Tensors: Finding the modulus (size), the angle between vectors (dot or inner product) and projections of one vector onto another and to examine how the entries describing a vector will depend on what vectors we use to define the axes
Matrices: Matrices can transform a description of a vector from one basis (set of axes) to another. For example, figuring out how to apply a reflection to an image and manipulate images.
Length squared sampling in matrices, Singular value decomposition, Low-rank approximation are few techniques which are widely used in the data processing.
For example, the singular value decomposition finds the best-fitting k-dimensional subspace for k= 1,2,3,…, for the set of N data points. Here, “best” means minimising the sum of the squares of the perpendicular distances of the points to the subspace, or equivalently, maximising the sum of squares of the lengths of the projections of the points onto this subspace.
SVD is traditionally used in the principal component analysis (PCA), which in turn is popularly used for feature extraction and for knowing how significant the relationship among the features or properties is to an outcome.
The word ‘mathematics’ brings in a ton of concepts — and this might scare away the beginners. However, if one manages to look closely, then much of the maths used in basic ML is usually covered in high school.
The whole point here is to find the distance between points, the shorter path between points and for this, one needs linear algebra.
Why Reinvent The Wheel, When We Have Python Libraries
There is no denying the fact that building ML algorithms from scratch is a thing of the past. Modern-day programming platforms offer plenty of options where a single line of code would invoke a monstrous algorithm in the background. This works for those who want to get an idea of how ML plays out. However, if one is even remotely serious about putting an ML model into production then many issues surface.
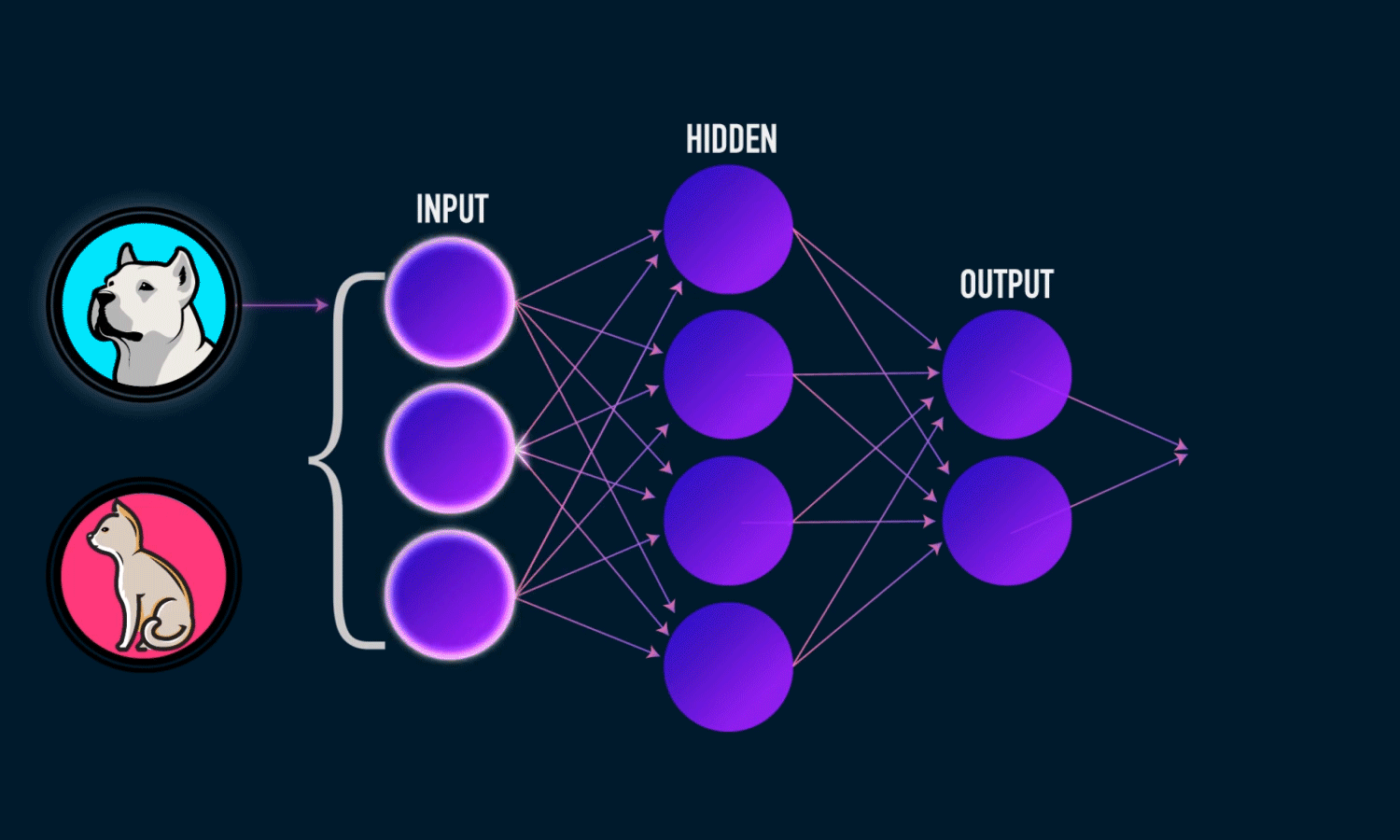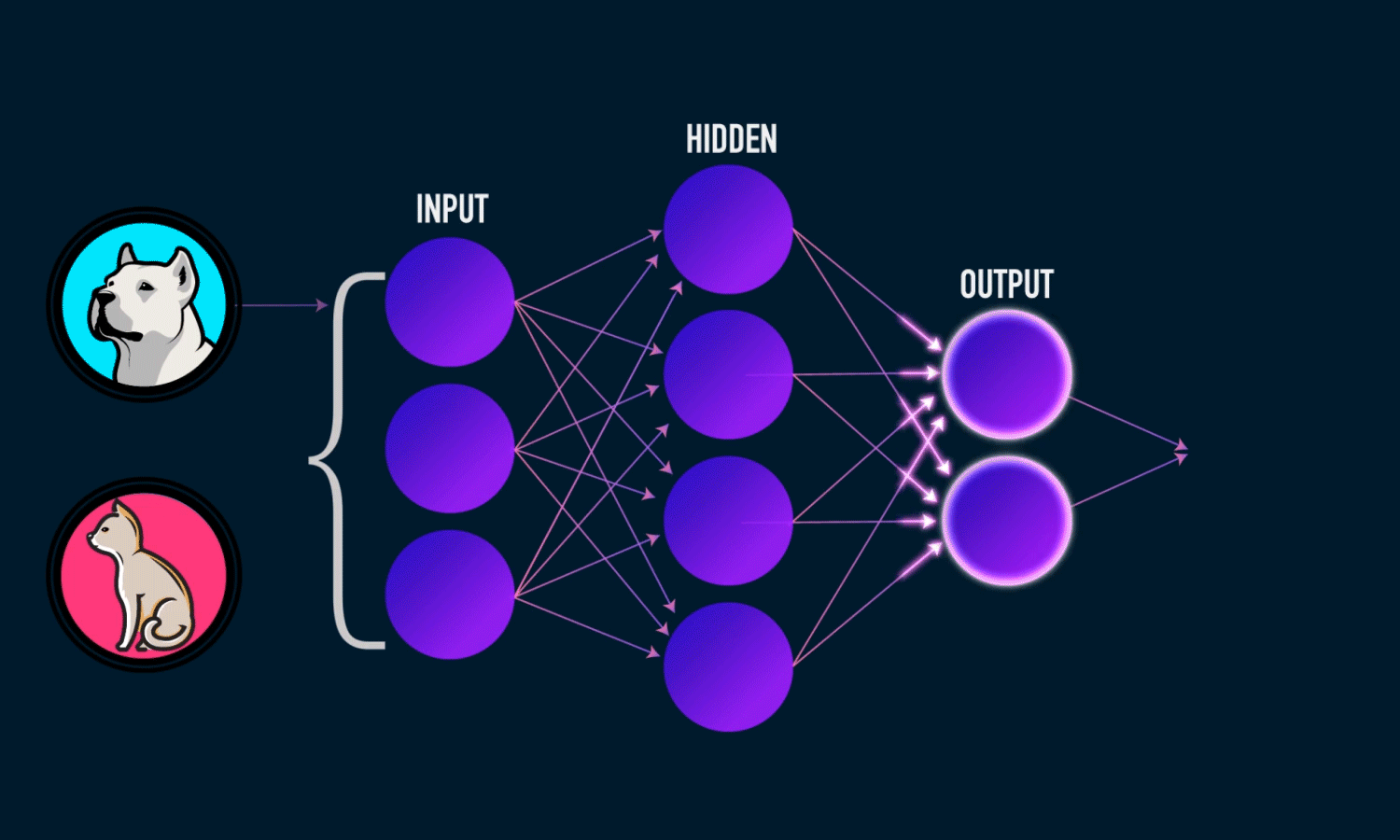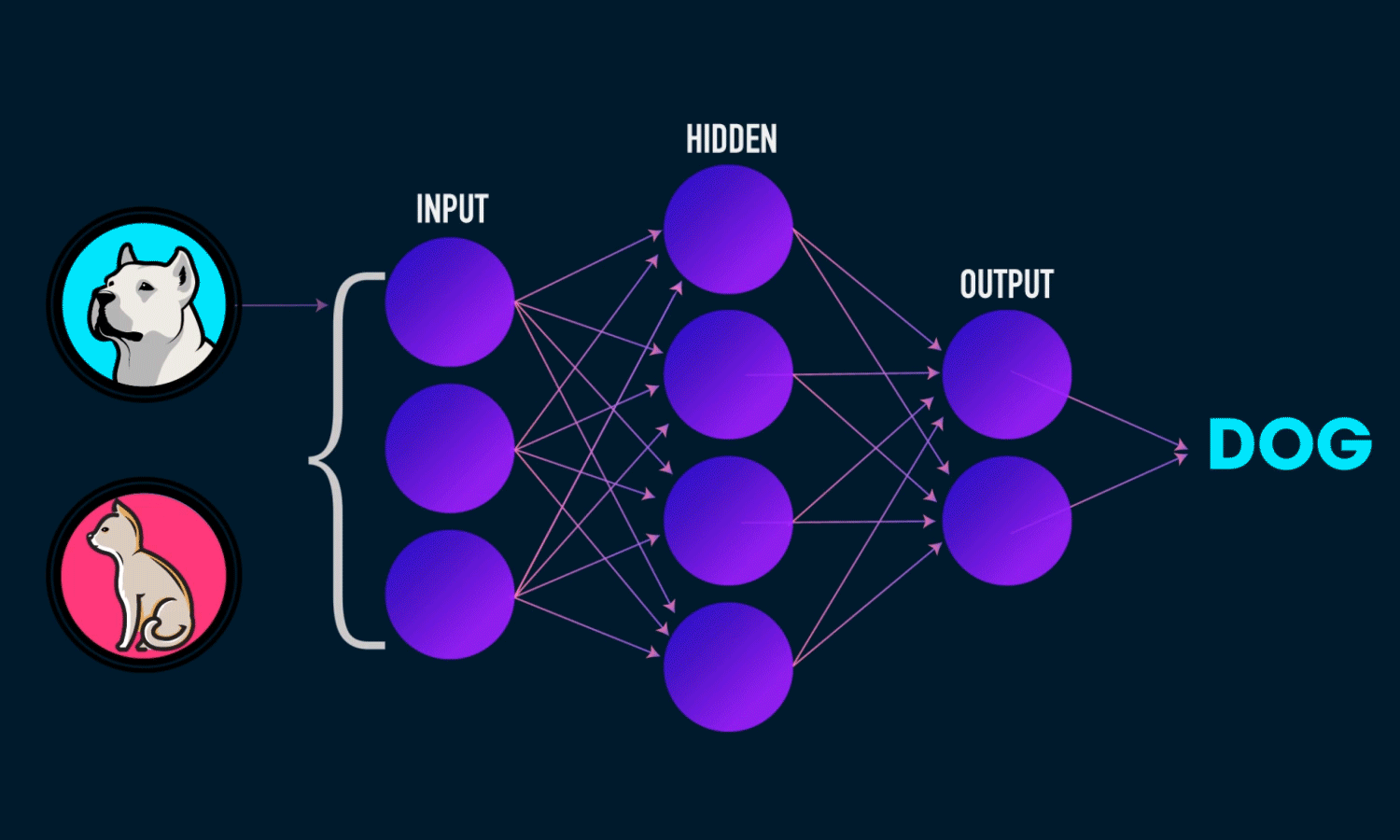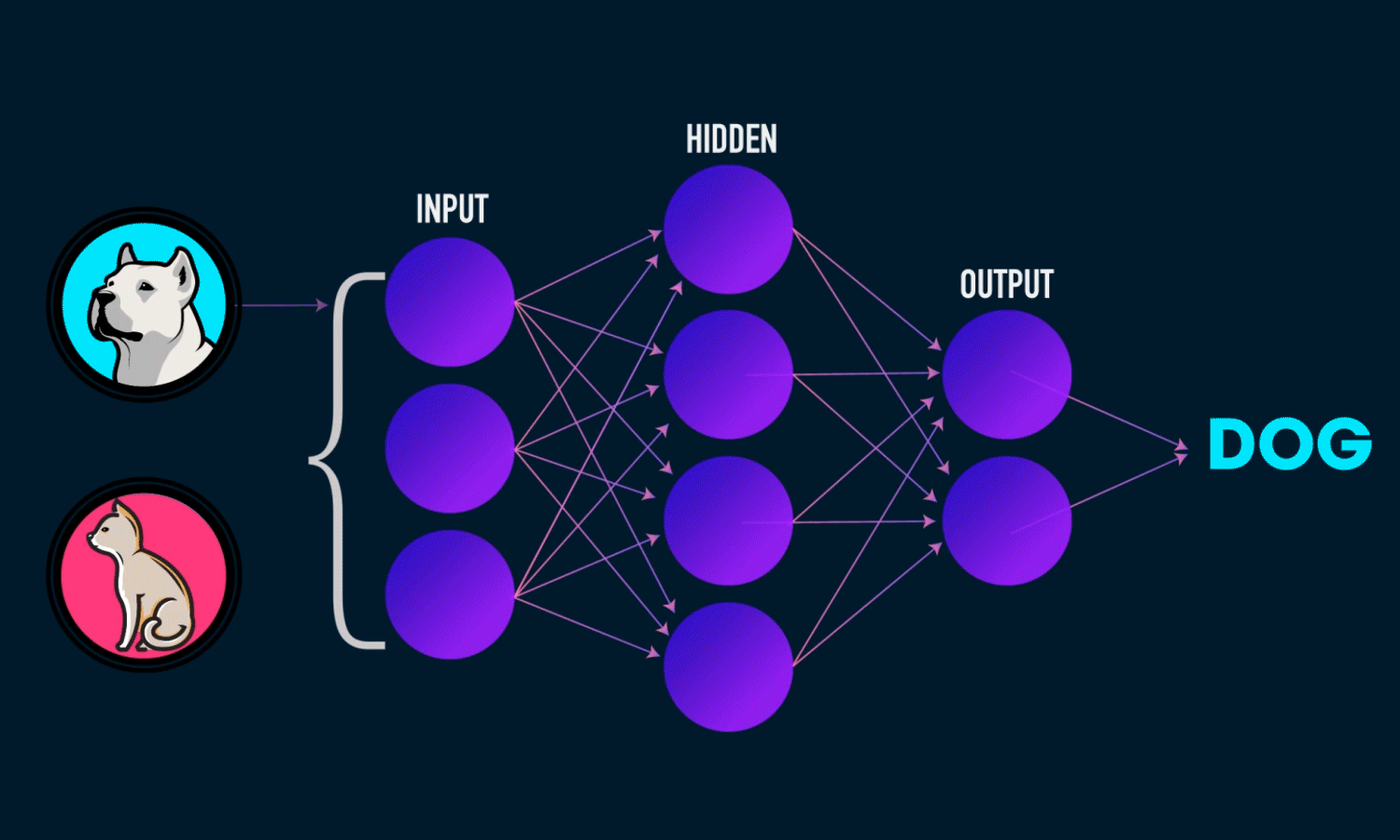
For instance, a neural network is built around simple linear equations like Y = WX + B, which contain something called as weights W. These weights multiply with the input X and play a crucial in how the model predicts. The prediction scores can go downhill if a wrong weight gets updated and as the network gets deeper i.e addition of more layers(columns of connected nodes), the error magnifies and the results miss the target.
Even to figure this out, one should have had already known of the presence of a system of simple equations that govern simple neural networks. With this knowledge, one can not only build the intuition of how a model performs but can also use it to compare with other models. Because, when we say a model is different, what it actually means is that equations are different.
One can build on this knowledge to learn about how the models optimise in the case of using gradient descent methods and how the change in learning rate signifies the performance of an algorithm.

The last century has seen tremendous innovation in the field of mathematics. New theories have been postulated and traditional theorems have been made robust by persistent mathematicians. And we are still reaping the benefits of their exhaustive endeavours to build intelligent machines. The field of machine learning is built on some ingenious mathematical and logical hypotheses and tools.
There are other rudimentary topics, which can make the life of a typical machine learning engineer easy:
- Law of large numbers
- The geometry of high dimensions
- Random walks in Euclidean space
- Gradient Descent methods
- Graph partitioning
- Bayesian or belief networks

















