



Decision Tree is the simple but powerful classification algorithm of machine learning where a tree or graph-like structure is constructed to display algorithms and reach possible consequences of a problem statement. This is a predictive modelling tool that is constructed by an algorithmic approach in a method such that the data set is split based on various conditions. Besides other classification methods of supervised learning, this method is widely used for practical approaches and can be used in both classification and regression problems. In general, this algorithm is referred to as Classification and Regression Trees (CART).
This article is meant for the beginners in machine learning who wants to deep dive from the scratch into this space.
How It Works
The supervised learning algorithm is always drawn upside down i.e. root is always at the top. The samples are split into two or more homogenous sets depending upon the differentiator in input variables.
For instance, let’s say we have a dataset of a population that includes two variables i.e. diabetic patients and non-diabetics. Now, in order to create a model to predict who is diabetic or non-diabetic, the tree will be traversed from root to leaf and it will be done till the criteria are fulfilled.
Some important cases are to be assumed to create a decision tree model
- The root node will be represented in the whole training set
- The nodes that do not split are called a leaf node
- The node which is divided into sub-nodes is called parent node and the sub-nodes are called as child-nodes.
- Records will be distributed recursively depending upon the attribute values
The model used here has three attributes and two classes. The attributes referred here are minimum systolic blood pressure, age and blood glucose level and the classes are diabetic and non-diabetic.
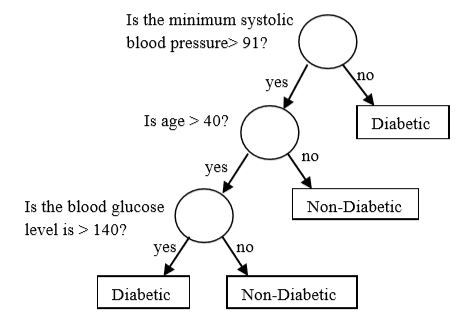
While modelling a decision tree we can use two methods to avoid over-fitting in the model. They are:
Pruning: This process involves the removing of branches that contains features of low importance for the model. It can be done either at the root or the leaves, but the simplest process will be done at the leaves.
Reverse Binary Splitting: All the features are taken into consideration in this process, then different split points are tried and tested. A cost function is used to split in the model that searches for the most homogenous branches having similar responses.
Learning The Decision Tree Algorithm
Step 1: Create The Root Node
Let us assume Sample S. The initial step begins with the calculation of Entropy H(S) of the current state of Sample S. The Entropy is said to be the measurement of the quantity of uncertainty in data. The formula of Entropy is shown below
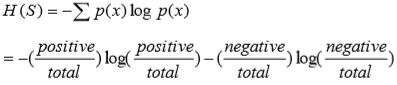
The value of Entropy will be zero if all the members resemble the same group and the value of Entropy will be one when fifty percent of the members belong to one particular class and the other fifty percent belongs to another class.
The following step is to select the attribute which gives us the Information Gain with the highest possibility and will be selected as the root node. Information gain is denoted by IG (S, A) for a sample S is the productive transform in entropy after deciding on a notable attribute A. Information Gain evaluates the relative transform in entropy in relation to the variables which are independent. The formula is given as:
![]()
Here, x denotes the feasible values for an attribute, H(S) is the Entropy of all the samples and P(x) is denoted as the possibility of the event x.
Step 2: If all the instances are found to be positive; Return leaf node as “positive‟.
Step 3: Else if all the instances are negative; Return leaf node as “negative‟.
Step 4: Remove the attribute which yields the highest Information Gain from the group of attributes.
Step 5: Repeat the process until the last attribute or the decision tree achieves all the leaf nodes.
Decision Tree In Real-Life Applications
- Business Management: The model of this algorithm is broadly applied for customer alliance administration and also the recognition of deception.
- Customer Relationship Management: Arrange Customer’s alliance by observing the use of online amenity.
- Fraudulent Statement Detection: Recognition of Fraudulent Financial Statements (FFS) because of the issues creating for tax income of the government.
- Engineering: For vitality utilisation and detect observation, Decision Tree is used.
- Energy Consumption: Supports the companies with the issues of consuming of the energy.
- Fault Diagnosis: Broadly utilised application in the field of engineering is the recognition of faults.
- Healthcare Management: With its advancement in everyday life, it is used in the field of heath-caring systems.
Advantages:
- Domain knowledge is not required for the decision tree construction
- Inexactness of complex decision is minimised which results to assign exact values to the outcome of various actions
- Easy interpretations and cope with numerical data and categorical data
- It performs categorisation without much computation
- Decision trees cope up with both continuous variables and categorical variables
Disadvantages:
- One output attribute is restricted for Decision Tree
- Decision Tree is an unstable classifier
- This algorithm generates categorical outputs
- Decision trees are not so suitable for task evaluating for prediction of the practicality.












































































