The number of songs available exceeds the listening capacity of an individual in their lifetime. It is tedious for an individual to sometimes to choose from millions of songs and there is also a good chance missing out on songs which could have been the favourites.
The number of songs available exceeds the listening capacity of an individual in their lifetime. It is tedious for an individual to sometimes to choose from millions of songs and there is also a good chance missing out on songs which could have been the favourites.
Music service providers like Spotify need an efficient way to manage songs and help their customers to discover music by giving a quality recommendation. For building this recommendation system, they deploy machine learning algorithms to process data from a million sources and present the listener with the most relevant songs.
There are mainly three types of recommendation system: content-based, collaborative and popularity.
The content-based system predicts what a user like based on what that user like in the past. The collaborative based system predicts what a particular user like based on what other similar users like.
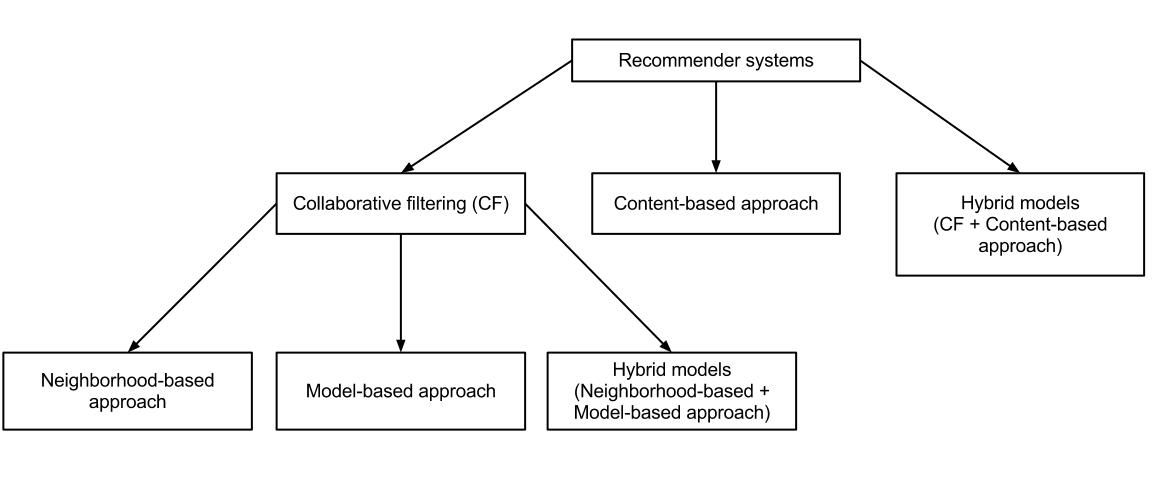
The problem with popularity based recommendation system is that the personalisation is not available with this method i.e. even if the behaviour of the user is known, a personalised recommendation cannot be made.
Here we illustrate a naive popularity based approach and a more customised one using Python:
# Importing essential libraries #
import pandas as pd
from sklearn.model_selection
import train_test_split
import numpy as np
import timefrom sklearn.externals
import joblib
import Recommenders as Recommenders
# Download this file into your source code directory#
import Evaluation as Evaluation
#The following lines will download the data directly#
triplets_file = 'https://static.turi.com/datasets/millionsong/10000.txt'
songs_metadata_file = 'https://static.turi.com/datasets/millionsong/song_data.csv'
song_df_1 = pd.read_csv(triplets_file, header=None, sep = "\t")
#in the above line the separator is a TAB hence \t otherwise the file is read as single column#
song_df_1.columns = ['user_id', 'song_id', 'listen_count']
song_df_1.columns = ['user_id', 'song_id', 'listen_count']
print(song_df_1)
#Read song metadata
song_df_2 = pd.read_csv(songs_metadata_file)
#Merge the two dataframes
song_df = pd.merge(song_df_1, song_df_2.drop_duplicates(['song_id']), on="song_id", how="left")
song_df.head()
len(song_df)
ong_df = song_df.head(10000)
#CREATING A SUBSET FROM THE DATASET#
#Merge song title and artist_name columns to make a merged column
song_df['song'] = song_df['title'].map(str) + " - " + song_df['artist_name']
song_grouped = song_df.groupby([‘song’]).agg({‘listen_count’: ‘count’}).reset_index()
grouped_sum = song_grouped[‘listen_count’].sum()
song_grouped[‘percentage’] = song_grouped[‘listen_count’].div(grouped_sum)*100
song_grouped.sort_values([‘listen_count’, ‘song’], ascending = [0,1])
# TRAINING AND TESTING THE DATA#
train_data, test_data = train_test_split(song_df, test_size = 0.20, random_state=0)
print(train_data.head(5))
#CREATING AN INSTANCE BASED ON POPULARITY#
pm = Recommenders.popularity_recommender_py()
pm.create(train_data, ‘user_id’, ‘song’)
#PREDICTING#
user_id = users[5]
pm.recommend(user_id)
#CREATING A CLASS FOR SONG SIMILARITY#
is_model = Recommenders.item_similarity_recommender_py()
is_model.create(train_data, 'user_id', 'song')
#RECOMMENDATION#
user_id = users[9]
user_items = is_model.get_user_items(user_id)
for user_item in user_items:
print(user_item)
#GET SIMILAR SONGS#
song = ‘Yellow – Coldplay’
is_model.get_similar_items([‘XYZ’])
Here a testing size of 20% is taken arbitrarily pick 20% as the testing size. A popularity based recommender class is used as a blackbox to train the model. We create an instance of popularity based recommender class and feed it with our training data.
train_data, test_data = train_test_split(song_df, test_size = 0.20, random_state=0)
print(train_data.head(5))
pm = Recommenders.popularity_recommender_py()
pm.create(train_data, 'user_id', 'song')
user_id = users[9]
pm.recommend(user_id)
Even if we change the user, the result that we get from the system is the same since it is a popularity based recommendation system.
This is a naive approach and not many insights can be drawn from this. To make a more personalised recommender system, item similarity can be considered.
Item Similarity Based Personalized Recommender
Memory based filtering mainly consists of two main methods:
- User-item filtering: Users who are similar to you also liked…”
- Item-item filtering: users who liked the item you liked also liked…”
Most companies like Netflix use the hybrid approach, which provides a recommendation based on the combination of what content a user like in the past as well as what other similar users like.
#Personalised System Part II
#Creating an instance of item similarity based recommender class
is_model = Recommenders.item_similarity_recommender_py()
is_model.create(train_data, 'user_id', 'song')
#Use the personalized model to make some song recommendations
#Print the songs for the user in training data
user_id = users[9]
user_items = is_model.get_user_items(user_id)
for user_item in user_items:
print(user_item)
#Recommend songs for the user using personalized model
is_model.recommend(user_id)
is_model.get_similar_items(['Mr Sandman - The Chordettes'])
song = ‘Yellow – Coldplay’
is_model.get_similar_items([song])
In item similarity, the main method is “generate_top_recommendation”. So, what this does is it creates a co-occurrence matrix. This matrix can be thought of as a set of data items containing user preferences.
A snippet of code from the file

Here songs are the items. We are calculating weighted average of scores in the co-occurence matrix for all user songs. Then the indices are sort based on their value and the corresponding score.
is_model = Recommenders.item_similarity_recommender_py()
is_model.create(train_data, 'user_id', 'song')
# this prints training data
user_id = users[5]user_items = is_model.get_user_items(user_id)
for user_item in user_items:
print(user_item)
is_model.recommend(user_id)
Output:

The output consists of user_id and its corresponding song name.
This article is an attempt to give a beginner, a guide on how to implement simple song recommender and talk in brief on how to execute the source code for simple application so that this can be taken further and experimented with.
Check the full notebook here.