






Even in 2018, there is a lot of interest in data science – it’s a high impact job that commands the best salary and has a huge demand. Now, the usual learning path follows a pattern – for years the data science route has been a combination of Python < R < Java & SQL. In between, data science enthusiasts also brush up on their linear algebra + probability, get hands-on experience on the Iris dataset by training a classifier, squeeze in a primer on Deep Learning by working their way through a TensorFlow tutorial.
Data Science is a broad topic and learners usually embark on the learning journey with a lot of motivation, but end up going in different directions and finally, come back to square one. While there is absolutely no replacement for a ‘learning on the job’—but how do you get that data science job in the first place? The truth is no one becomes an expert in data science before getting a job in data science.
Let’s chalk out the usual path for data science enthusiasts:
- Learn Python < R < SAS < SQL
- Learn descriptive statistics, hypothesis testing, probability
- Become well-versed in the various types of Machine learning algorithms — Supervised, Unsupervised
- Finally learn Data Visualization tools like Tableau
Now, even if you are following a guided learning path (aka an online certification) with paid courses that feature Capstone Projects it may not give you the edge in a real job. One major disadvantage associated with Capstone projects is that the datasets are often clean, curated and have a specific purpose – they are good enough to give one a head-start but don’t really pack a punch.
Even in 2018 the big question remains the same – if one wants to transition to a Data Scientist role, what should be the logical path? Would a long-term course or a bunch of certifications help in getting a junior data scientist role or should one try to transition internally? For some recruiters, online courses don’t really hold much weight, so how does one prove you have the skills to potential employers. There may be individuals who will get the required skills but lack a portfolio to bolster their resume.
What’s the best way to learn data science in 2018?
Let’s face it, if you are a data science enthusiast, you must be having a limited experience with Python, some knowledge of databases, strong background in mathematics and a basic knowledge of statistics.
Let’s approach the learning in a slightly different way. AIM presents an outline on how to become a data scientist in 2018:
a) Zero Python experience – beef up Programming & DB side: Focus on learning Python programming for the next six months and interacting with a database via python. Then once you have a good understanding of python and programming in general, start learning the machine learning packages (prefer starting with scikit-learn).
Recommended:
- Download Python Essential Reference 4th Edition by David M Beazley 2009 here
- Download Programming Python, 4th Edition Powerful Object-Oriented Programming here
- Follow the official blog of Python Software Foundation and join the growing community (they are always on a lookout for contributors). As of 2017,
b) Get started on scikit-learn, the best data analysis and data mining tool: The goal of learning Python should be to get started by making simple models using scikit-learn. Next, practice your skills through that using tutorials on Kaggle like https://www.kaggle.com/c/titanic. Once you join Kaggle, don’t go on to expect to win competitions, but look at them as a way to gain real experience and mentoring from the community.
Recommended: Check out this excellent repository scikit-learn, best-suited for a machine learning beginner or anybody who wants to master Scikit-learn. From instructions on installation to user guide and general purpose plus introductory examples, Scikit Learn is a great place to get started.

c)Learn Jupyter/ipython notebooks: Your next step should be to learn to use Jupyter/ipython notebooks, and embed charts in them. Jupyter notebook, were previously known as the IPython notebook, and it is the best tool to drum up analyses, as you can keep code, images, comments, formulae and plots together.
Recommended: Here’s a quick start guide on Jupyter/IPython Notebook. Also check out this 30-minute explainer video that goes from install < setup < using Jupyter Notebook.
d) Leaning towards data engineering, focus on database section: The choice is yours – do you want to build models or clean data? In our view, learning SQL is more important than learning NoSQL. And to succeed in this field, you need more than a bare minimum of SQL with relational database (MySQL, PostgreSQL). If you are a complete newbie, spend some time on understanding relational databases, datatypes (e.g. numeric, strings) & joins methodology.
Recommended: There are plenty of resources on SQL on the web & w3schools SQL tutorial is one of the most popular. For those who have excellent spreadsheet skills and want to pivot to SQL, check this out: Treasure Data.
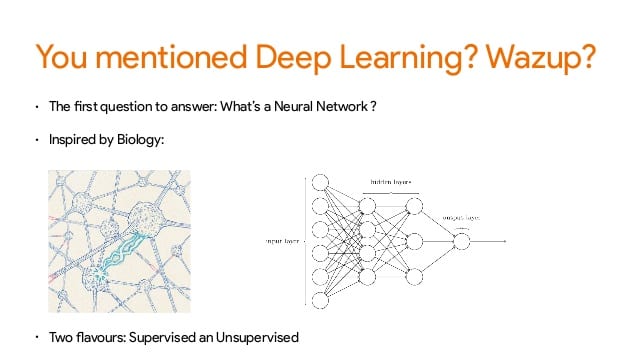
e) Don’t want a generalized route, looking for specialization in Deep Learning: Deep Learning is no longer just an industry buzzword and it has quickly gained traction for its impeccable accuracy. In view of recent tech trends, DL has become an core component of the data science toolbox. So, if you have a background in backpropagation and gradient descent, there are plenty of tutorials that will teach you how to code your first neural network with TensorFlow.
When it comes to Deep Learning, Google’s TensorFlow has emerged as the frontrunner, followed by Keras. One of the most interesting points about TensorFlow is that it’s written in C++, which was a leading programming language in data science. Another important point is that TensorFlow runs on a Python interface which sits on top of the C++ foundation. This means, developers don’t have to know C++ to code with TensorFlow. Plus, another big advantage TensorFlow has over other framework, specifically Theano is that it supports multi-GPU out of the box, and startup time is much quicker.
Recommended: There are plenty of tutorials on Tensorflow.org to help you build neural network from the basic building blocks. However, one has to be comfortable in Python before starting DL training. Also, prep yourself with Numpy, Scipy, Pandas, and Matplotlib stack before diving into DL.
Last Word
There is no generalized route to succeed in data science and most programmers look for certain specializations. Also, it is easy to get lost in too much theory, so it is important to stay grounded by doing as much practical as possible. We recommend starting a GitHub account to showcase your projects and gather feedback from peers.


















