



Personalisation is the new mantra for retailers today. However, that should not be limited only for the customers but also be adopted as a strategy towards growing store sales. ‘One-size-fits-all’ approach would no longer work for achieving strong store-level growth and it is important to customise a strategy for each store. Clustering of stores based on characteristics beyond store sales or region will enable retailers to identify a cluster of stores that would match each other closely on multiple dimensions. Brick-and-mortar retailers can begin their store level personalisation journey in three steps:
- Identify variables for clustering: Variables that define variation in-store performance should be identified to create clusters.
- Business validation of emerging clusters: Store clusters identified based on variables should be stress-tested against business logic to ensure relevance for decision making.
- Periodic refresh of clusters: Fast changing trends and consumer preferences would also require retailers to periodically refresh their store clusters which directly impact the customer experience.
Personalisation Strategy Must Be Applied To Stores For Driving Sales Growth
The retail world is moving towards a highly customised and personalised experience for its customers. In the endeavour to know their customer better, retailers are collecting and crunching huge data sets. However, the personalisation should not be restricted to external entities, such as customers, but also apply to internal strategy and planning. ‘One-size-fits-all’ is an approach of the past even when thinking about retail store planning and growth.
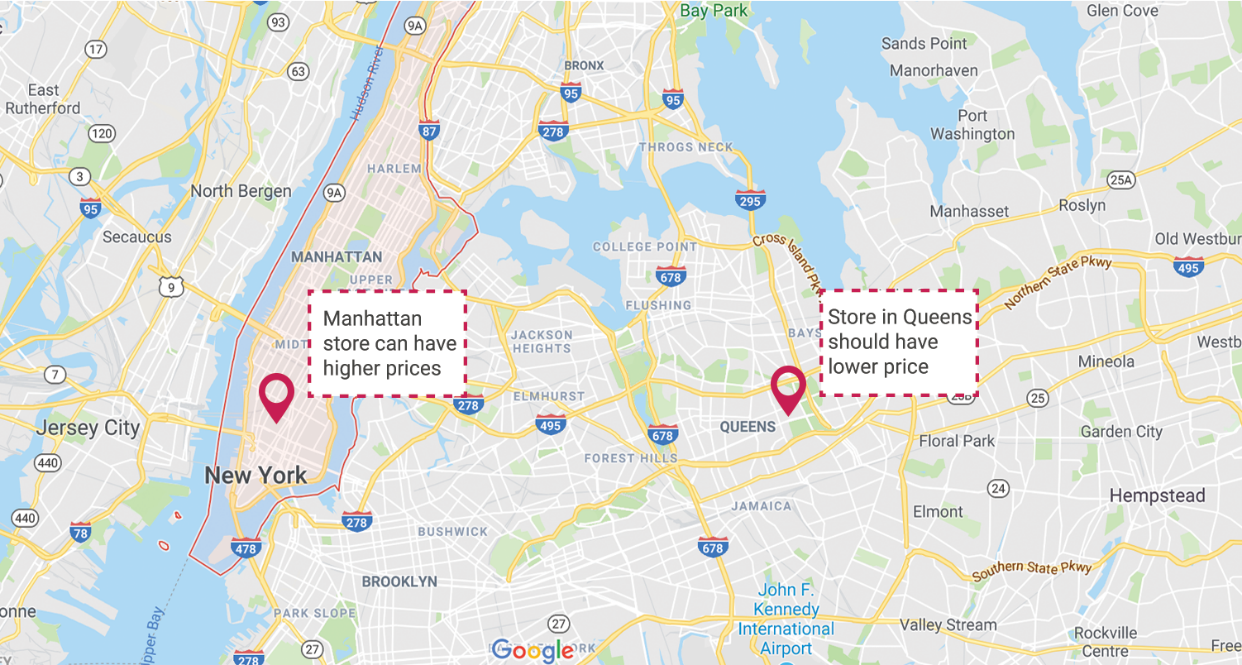
For example, a QSR (Quick Service Restaurant) chain’s outlet in Manhattan can price their products higher than the outlet in Queens as Manhattan customers would prefer a quicker service and not be as sensitive to prices. At the same price, the QSR chain is either making less money in their Manhattan store or losing sales in Queens due to the higher prices. Such customised strategy can be designed and executed on the back of an analytics-driven store clustering. Dividing stores into clusters of similar attributes can help drive higher revenue and better customer experience leading to increased margins.
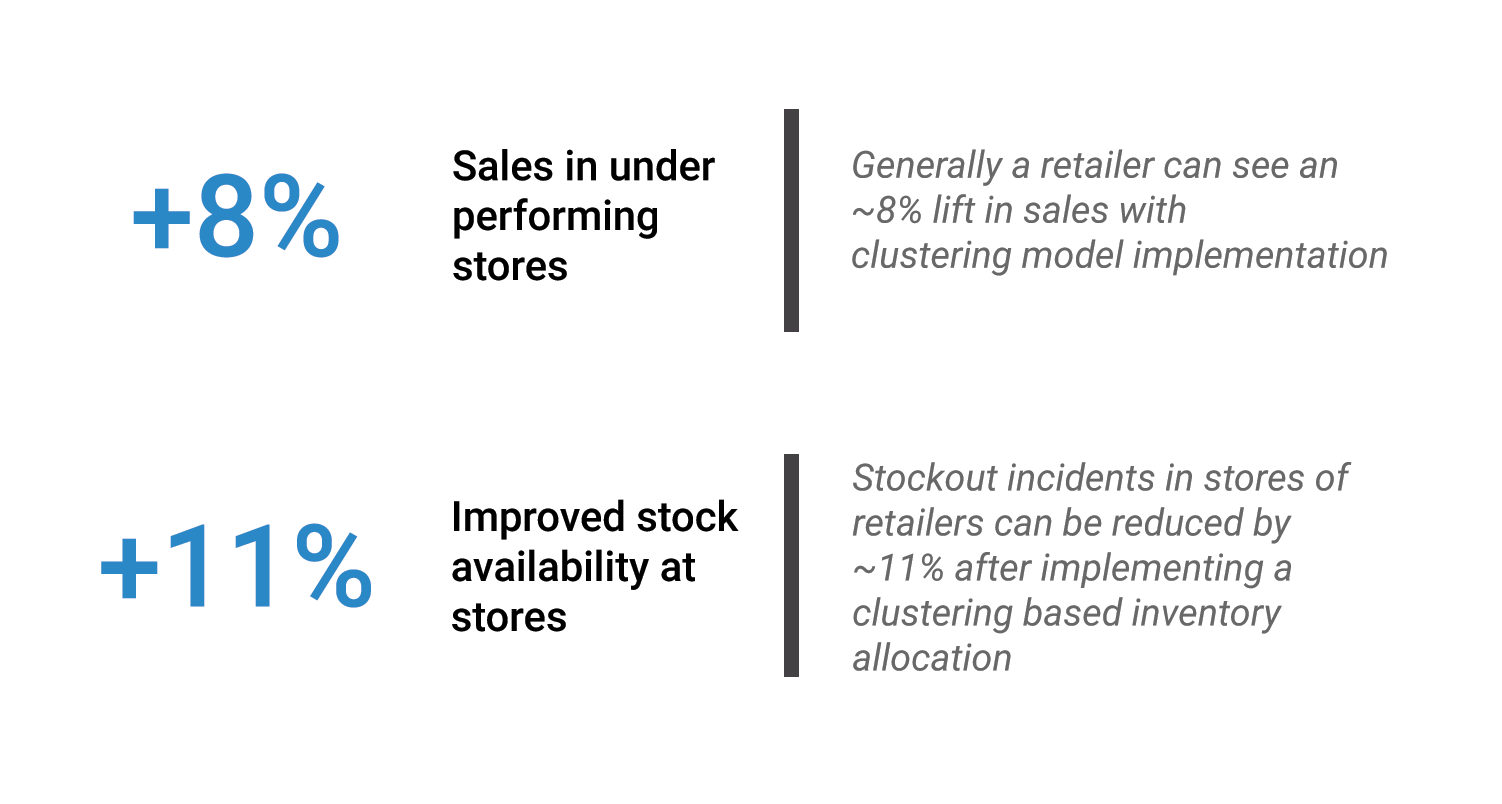
Store-Level Execution Strategies Can Result In Enhanced Bottom-line Benefits For Retailers
Store personalisation can enable same-store sales growth. Planning and store clustering can be done using a geographic and revenue-based approach that could lead to multiple clusters. New store clustering can be developed based on a combination of attributes like store age, revenue growth, local demographics, competition intensity and product split.
A simple tool can be set-up to view the cluster parameters and store tagging to the clusters. An auto-refresh cadence can also be used for refreshing the clustering every quarter based on changing the performance of the stores.
Identify Factors, Create Models, Check Applicability
Historically, stores have been segmented based on the regions primarily from a better operations and organisation management perspective. Store clustering is an iterative process of sifting through myriad store characteristics to form multiple clustering models, of which, some pass the test of business suitability. The models won’t be fixed and would require a constant refresh to accommodate for changing market forces.
The resulting store clusters can help retailers to create customised cluster level execution strategies pertaining to promotions planning, pricing, markdown/clearance planning, new product launch, assortments, inventory and labour staffing.
Variable selection and tuning are unique to each business and would play out in different ways. For example, for apparel retailers, the weather conditions are important to plan assortments differently for stores in NYC / DC than those in LA / SFO. Similarly, for a large sporting goods retailer, it is possible that a category-wise split of revenue helps managers in inventory planning to ensure that customer preferences are met in the store. Stores that have higher sales contribution from cycling equipment could have larger display areas for cycles and could stock more to ensure that there is no sales loss due to item unavailability, whereas the stores with less contribution from cycling equipment could have smaller display area for cycles and could do with lesser stocks of cycles thereby not locking up their working capital in stocking more cycles.
Successful Clustering Is The Result Of Confluence Of Data Science And Business Validation
The best results can be achieved with the mix of data science techniques and business acumen put together which can span across four key steps:

- The implementation process starts with creating a long list of possible variables that can be used to cluster the stores. This list is typically based on the business importance of variables as well as the availability of accurate data. For example, variables used can be the parking availability at stores, Wi-Fi bandwidth, seating capacity, revenue per staff member and many more.
- Variable selection becomes a critical part of the clustering implementation because any clustering based on more than 5 variables would typically make the exercise very complex and tough to understand for the business teams. The goal of variable selection is to minimise the clustering variables while still explaining the variation across clusters. PCA, CCA, factor analysis, etc. can help identify covariance among variables to eliminate similar variables for the clustering.
- Once the variables for clustering are selected, the next step is to build and execute different clustering models. A mix of unsupervised and supervised clustering models are run and passed through the elbow test to ascertain the right numbers of clusters. Generally, 5-7 clusters are great as an end result where each cluster can also be justified with a business definition. Combination of 2-3 model outputs is then used to create final clusters using the selected variables.
- Final and the most important step is to establish that the clusters really differ in their performance, business metrics or definition. If, however, the clusters do not pass through the test of business judgment, the exercise is repeated from step 2 again.
Conclusion
For any large retailer, insights into the drivers of success for a store provide a huge competitive edge. However, retailers can no longer adopt a uniform strategy for all their stores which are spread across the country. Stores in different regions with diverse customer purchase behaviour will need personalised strategies to continue their growth story which can be replicated at other stores with similar characteristics.
Also watch:















































































