



Marcel Proust, in his ‘Remembrance of Things Past’, wrote that a bite of a madeleine made him feel nostalgic about his aunt giving him the very same cake before going to mass on a Sunday.

A fully functional olfactory system is considered to be linked to memory more so than other senses. Humans are equipped with 5 senses. They can smell what is cooking next door. Even can guess the food item with a blindfold on, just by touching and feeling the texture or by grasping the shape. One can even recognise the sound of coconut crashing onto the floor. But can humans guess the recipe of a dish just by looking at it? Maybe, maybe not.
But, for machines, this is a gigantic and almost impossible task. For all, it is fed with are a bunch of pixels. A group of researchers from Universitat Politecnica de Catalunya, Spain along with Facebook AI tried their hand at the same. They developed a system that can predict ingredients and then generates cooking instructions by attending to both image and its inferred ingredients simultaneously.
Challenges With Picture Only Input

The high-quality food pictures online often distort reality. The contents can be misrepresented and pose a challenge to recognition systems. Few challenges include:
- When compared to natural image understanding, food recognition poses additional challenges, since food and its components have high intra-class variability and present heavy deformations that occur during the cooking process.
- Ingredients are frequently occluded in a cooked dish and come in a variety of colors, forms and textures.
- Visual ingredient detection requires high-level reasoning and prior knowledge.
Existing methods have only made an attempt and ingredient categorization and not on the preparation process. These systems fail when a matching recipe for the image query does not exist in the static dataset
Formulating Inverse Cooking
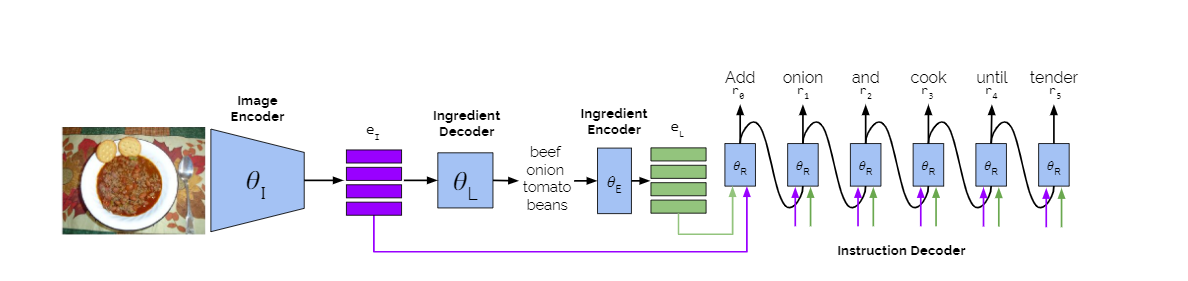
Traditionally, the image-to-recipe problem has been formulated as a retrieval task where a recipe is retrieved from a fixed dataset based on the image similarity score in an embedding space.
In this model, the images are extracted with the image encoder and parameterised. Ingredients are predicted and encoded into ingredient embeddings. The cooking instruction decoder generates a recipe title and a sequence of cooking steps by attending to image embeddings, ingredient embeddings and previously predicted words.
The attention module in the transformer network is replaced with other attention strategies namely concatenated, independent and sequential to guide the instruction generation process.

Recipe generation for Biscuits via paper by Amaia Salvador et al.,
This system was evaluated on the large-scale Recipe1M dataset that contains images of 1,029,720 recipes scraped from cooking websites.
The dataset contains 720,639 training, 155,036 validation and 154,045 test recipes, containing a title, a list of ingredients, a list of cooking instructions and (optionally) an image.
For the experiments, authors have used only the recipes containing images, and have removed recipes with less than 2 ingredients or 2 instructions, resulting in 252,547 training, 54,255 validation and 54,506 test samples.
Future Direction
The food patterns have changed over the centuries. Unhealthy eating habits and diet-conscious culture have grown simultaneously. People have formed their own communities around the diet they follow. People are serious about what they put into their mouth.
A prepared meal at the restaurant can have many ingredients. And, a curious customer can fire up an app on their smartphones that runs inverse cooking machine learning model and comes up with the ingredients. These innovations are not an end in themselves but are a platform to serve more such ideas.
Download the pre-trained model here.
Read the full paper here.









































































