






Experiments like Sketch-RNN, Google’s experiment with AI, showed the world how well AI can draw. With Sketch-RNN, the drawing is passed through recurrent neural networks which have been trained on millions of doodles collected from the Quick, Draw! game. Built on TensorFlow, Sketch-RNN demonstrated many possible ways to sketch and produce. For example, by mimicking drawings, producing similar doodles or completing the incomplete paintings done by humans.
Now, AI can produce artwork just by following your text-based command. Like seen in the picture below, when passed instructions in plain English, the model comes up with an understandable art with a boy, girl, sandbox, hot dog and a shovel.
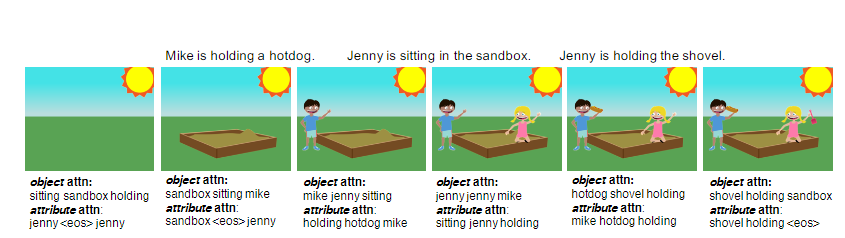
Researchers at the University Of Virginia in collaboration with IBM Watson, propose Text2Scene, a model that generates various forms of compositional scene representations from natural language descriptions.
Generating art has become popular with the flourishing of GANs but in this work, researchers claim that Text2Scene model is competitive and also can produce superior interpretable results.
AI-Art Without GANs
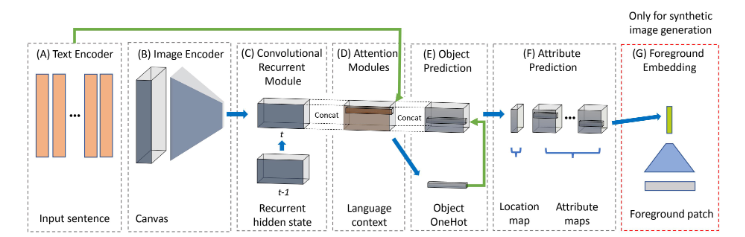
As can be seen in the above illustration, the general framework of Text2Scene consists of
- (A) a Text Encoder that produces a sequential representation of the input,
- (B) an Image Encoder that encodes the current state of the generated scene,
- (C) a Convolutional Recurrent Module that tracks, for each spatial location, the history of what has been generated so far,
- (D-F) two attention-based predictors that sequentially focus on different parts of the input text, first to decide what object to place, then to decide what attributes to be assigned to the object, and
- (G) an optional foreground embedding step that learns an appearance vector for patch retrieval in the synthetic image generation task
The text-to-scene is modelled using a sequence-to-sequence approach. In this approach, the objects are placed sequentially on an initially empty canvas.

The above picture consists of Sample inputs (left) and outputs of Text2Scene model (middle), along with ground truth reference scenes (right) for the generation of abstract scenes (top), object layouts (middle), and synthetic image composites (bottom).
The text “elephants walking together in a line” also implies certain overall spatial configuration of the objects in the scene.
The model modifies a background canvas in three steps:
- The model attends to the input text to decide what is the next object to add, or decide whether the generation should end;
- If the decision is to add a new object, the model zooms in the language context of the object to decide its attributes (e.g. pose, size) and relations with its surroundings (e.g. location, interactions with other objects);
- The model refers back to the canvas and grounds (places) the extracted textual attributes into their corresponding visual representations.
The text encoder in the framework is basically a bidirectional recurrent network with Gated Recurrent Units (GRUs). It is a function of word embedding vectors, hidden vectors encoding the current word and its context.
At each step in the process, Text2Scene model predicts the next object from an object vocabulary with the help of a convolutional neural network(CNN). And, to capture small objects, a one-hot vector of the object predicted at the previous step is also provided as input to the downstream decoders.
To check the model’s validity, the following datasets were used:
- Clip-art Generation on Abstract Scenes dataset, which contains over 1,000 sets of 10 semantically similar scenes of children playing outside. The scenes are composed of 58 clip-art objects.
- Semantic Layout Generation on COCO – The semantic layouts contain bounding boxes of the objects from 80 object categories defined in the COCO dataset.
The results show that Text2Scene model outperforms other models like AttnGAN. But the authors agreed that their model can be further improved by incorporating more robust post-processing or in combination with GAN-based methods.
Models such as these stand as testimony to the fact that artificial intelligence is closing gap between itself and human intelligence. By mastering acts which are considered to be trivial by humans, AI is opening doors for multiple applications. For instance, the success of Text2Scene model can help capture criminals by generating sketches out of vague instructions or this model can be used to develop artful storyboards just by feeding the script.
Read the original paper here.


















