



The components of time-series are as complex and sophisticated as the data itself. With increasing time, the data obtained increases and it doesn’t always mean that more data means more information but, larger sample avoids the error that due to random sampling.
For social media platforms, the data handling chores get worse with their increasing popularity. Social media outlets like Twitter have imbibed many techniques over the years to offer uninterrupted services. In other words, handling tonnes of data, curating the data, forecasting the surge in data, gauging the time series with inbuilt metrics and then storing these metrics to make the whole thing more robust.
According to Twitter’s software engineering team, the networking giant stores 1.5 petabytes of logical time series data, and handles 25K query requests per minute.
The scale at which these firms operate requires customised in-built techniques. Twitter has done the same to solve their database challenges with MetricsDB.
There is a dedicated team for observability engineering at twitter which supports other teams which monitor service health and issues with distributed system.
What Does MetricsDB Offer

Previously, Manhattan was the go-to solution for Twitter. But this was not feasible as it required to use multiple datasets for every zone. MetricsDB, on the other hand, is multi-zone compliant.
The main objective of having these services is to have better monitoring, visualization, infrastructure tracing and log aggregation/analytics.
For storing mappings from partitions to servers, MetricsDB’s cluster manager uses HDFS.
The Hadoop Distributed File System (HDFS) is a distributed file system designed to run on commodity hardware.
Applications that run on HDFS have large data sets. A typical file in HDFS is gigabytes to terabytes in size. Thus, HDFS is tuned to support large files. It provides high aggregate data bandwidth and supports tens of millions of files in a single instance.
The partitions in the metrics database have a cluster manager of their own. The back end servers get updates from these cluster managers.
These backend servers are responsible for processing metrics for a small number of partitions. These servers store latest two hours of data and the older data gets cached. For checking this every two hours, Twitter uses Blobstore, durable storage that enables lower management head.
In the context of Twitter, a request can be something as important as user checking missing data. These missing data alerts would fire if the replica that responds first doesn’t have the data for the more recent minute. This is one way of knowing that the services are interrupted and inconsistencies have to be attended to.
So whenever a query pops up, the custom partition scheme uses consistent hashing on zone, service and source to route request to the specific logical backend. This reduces the number of individual metric requests per minute from 5 billion to under 10 million.
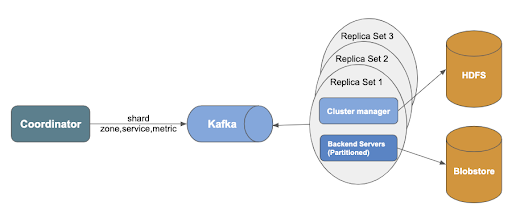
Few challenges still persist. For instance, a write request from a collection agent needs to be split into multiple requests based on a partitioning scheme. To address this, engineers have used Apache Kafka, which helped reduce the number of requests to the queue and storage.
Key Takeaways
- Using a custom storage backend instead of a traditional key-value store reduced the overall cost by a factor of 10.
- Ninety-three per cent of timestamps can be stored in 1 bit and almost 70% of metric values can be stored in 1 bit.
- Reduced latency by a factor of five.
- Improved responsiveness significantly while reducing the load.
The success that Twitter enjoys owes in large to its pursuit of freedom from physical enterprise vendors right from the beginning. They have continually engineered and refreshed their infrastructure by taking advantage of the latest open standards in technology.
Currently, enterprises are struggling to deploy machine learning models at full scale. Common problems include- talent searching, team building, data collection and model selection to say few. To tap the most out of the latest technologies, it is necessary to build service-specific tools and frameworks in addition to the existing models and the success of Twitter verifies the same.















































































