



The International Conference on Learning Representations (ICLR) is one of the highly regarded deep learning conferences conducted every year at the end of spring. The 2019 edition witnessed over fifteen hundred submissions of which 524 papers were accepted.
ICLR considers a variety of topics for the conference, such as:
- Feature learning
- Metric learning
- Compositional modelling
- Structured prediction
- Reinforcement learning
- Issues regarding large-scale learning and non-convex optimisation
Here are few works (in no particular order) presented at the recently concluded ICLR conference at New Orleans, US, which make an attempt at pushing the envelope of deep learning to newer boundaries:
Ordered Neurons: Integrating Tree Structures into Recurrent Neural Networks – MILA And Microsoft Research
Usually, Long short-term memory (LSTM) architectures allow different neurons to track information at different time scales but they do not have an explicit bias towards modelling a hierarchy of constituents.
This paper proposes to add an inductive bias by ordering the neurons (ON), which ensures that when a given neuron is updated, all the neurons that follow it in the ordering are also updated.
The results in this study show that recurrent architecture, ordered neurons LSTM (ON-LSTM), achieves good performance on language modelling, unsupervised parsing, targeted syntactic evaluation, and logical inference. This work had also been awarded the ‘best paper’ award.
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks – MIT CSAIL
This is one of the two papers which got top honours at ICLR 2019. Here, the authors propose a lottery ticket hypothesis which states that dense, randomly-initialised, feed-forward networks contain subnetworks (winning tickets) that — when trained in isolation — reach test accuracy comparable to the original network in a similar number of iterations.
One of the findings from this work is how consistent are the winning tickets that are less than 10-20% of fully-connected and convolutional feed-forward architectures for MNIST and CIFAR10. And, the results show that anything above this threshold leads to the winning tickets learning faster than the original network and attains higher test accuracy.
Analysing Mathematical Reasoning Abilities Of Neural Models – DeepMind
Understanding nature by using mathematics as a tool is one of the finest abilities of human beings. This ability is rarely intuitive and has to be learned through inferring, learning axioms, symbols, relations and properties. In this paper, the DeepMind researchers investigate the mathematical reasoning abilities of neural models.
The authors present methods to evaluate this ability through the structured nature of the mathematics domain to enable the construction of training and test splits designed to clearly illuminate the capabilities and failure-modes of different architectures.
Adaptive Gradient Methods With Dynamic Bound Of Learning Rate- Peking University
This paper introduces new variants of ADAM and AMSGRAD, called ADABOUND and AMSBOUND respectively to achieve a gradual and smooth transition from adaptive methods to Stochastic Gradient Descent(SGD) and give a theoretical proof of convergence.
The authors also demonstrate that these new variants can eliminate the generalisation gap between adaptive methods and SGD and maintain higher learning speed early in training at the same time.
Generating High Fidelity Images With Subscale Pixel Networks And Multidimensional Upscaling – Google
Autoregressive models are known to generate small images unconditionally but a problem arises when these methods are applied to generate large images. In this paper, the authors propose the Subscale Pixel Network (SPN), a conditional decoder architecture that generates an image as a sequence of image slices of equal size.
And, to address the challenge of the sheer difficulty of learning a distribution that preserves both global semantic coherence and exactness of detail, the researchers propose to use multidimensional upscaling to grow an image in both size and depth via intermediate stages corresponding to distinct SPNs.
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations- University Of California
In this work, the researchers, discover ways to enhance corruption and perturbation robustness. And, propose a new dataset called ImageNet-P which enables researchers to benchmark a classifier’s robustness to common perturbations. This paper is an attempt to establish rigorous benchmarks for image classifier robustness.
ALISTA: Analytic Weights Are As Good As Learned Weights in LISTA From UCLA
LISTA (learned iterative shrinkage-thresholding algorithm), have been an empirical success for sparse signal recovery. In this paper, Analytic LISTA (ALISTA) is proposed, where the weight matrix in LISTA is computed as the solution to a data-free optimisation problem, leaving only the step size and threshold parameters to data-driven learning. In other words, relatively more transparent and less black-box kind of training.
These are only a few of the accepted papers and it is obvious that the researchers from Google, Microsoft, MIT, Berkeley are one of the top contributors and collaborators for many works. Here is an infographic showing top contributors.
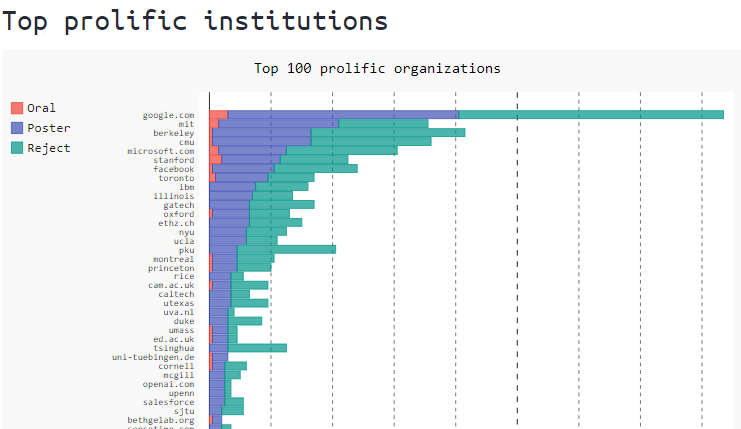
Source: prlz77
Check out the full list of accepted papers here.















































































