






While the advancements in deep learning and neural network algorithm have brought some interesting innovations in the last few years, they have their own set of challenges. Researchers have now found that these advancements may pose security threats as it involves a large set of data that it is dealing with. While we have seen attacks such as IoT botnet attacks, phishing attacks or crypto-ransomware attacks in the past, neural networks can pose these threats too.
This article largely talks about how deep learning and the neural network is on the verge of facing serious security threats.
Good Data, Bad Data
The most captivating and agitating task of deep learning is to enable machines to learn without human supervision. While cracking the brain function is hard, neural network tries to imitate the actions based on the data that it is fed with. Deep learning and neural networks fail to manage this unpredictability, bringing out the worst in a few cases.
Adversarial Attacks Of Neural Networks: Use Cases
Fooling Neural Networks
In a study by MIT researchers, they proved that Neural Networks can be fooled by 3D adversarial objects by making slight changes in a toy turtle that can make it identify it as a rifle.
The 3D printed turtle shown here is recognised as a rifle from every viewpoint by Google’s InceptionV3 image classifier. The researchers at MIT used a new algorithm that can cause misclassification of transformations like blur, rotation, zoom, etc. from any angle and used the new algorithm to generate on 2D printouts as well as 3D models.

It can be attributed to the fact that the decision-making process of a neural network is not the same as that of a human brain. However, this can be fixed in most cases by feeding more training data and readjusting its inner parameters.
Fooling Computer Vision
In another research, AI researchers at University of Michigan, Washington, Berkley including Samsung Research America and Stony Brook University showed how to fool a computer vision algorithm by proposing a general attack algorithm, Robust Physical Perturbations (RP2), to generate robust visual adversarial perturbations under different physical conditions.
They used the real-world case of road sign classification to show the adversarial effects that is generated through RP2 achieve high targeted mis-classification rates against the normal and standard road sign classifications including the viewpoints. They applied simple black and white stickers on road stop sign and achieved a maximum rate of mis-classification, thus evaluating the efficacy of physical adversarial manipulations on real-world objects.

Fooling Facial Recognition
In a study at Carnegie Mellon University, researchers were able to mislead neural network to another person by wearing a special pair of glasses that cost around $.22 per pair of glasses.
They developed a method that systematically as well as automatically generates physically realisable and inconspicuous attacks, allowing an attacker to dodge recognition or impersonate any other person. The method is realised by printing a pair of glasses which costs around $.22 per pair of glasses. When an attacker wore the glass and its image is supplied to a state-of-the-art face recognition algorithm, the outcome is an image of a completely different person, hence evading the recognition of the attacker’s identity.
 Figure: The upper three are the original pictures, the bottom three pictures are the output.
Figure: The upper three are the original pictures, the bottom three pictures are the output.
Fooling Speech Recognition
A research by Nicholas Carlini, David Wagner at the University of California, Berkley applied adversarial attack on speech recognition algorithm by manipulating an audio file in such a manner that it would go unnoticed to normal ears but may lead to an artificial intelligence transcription system to give a completely different result.
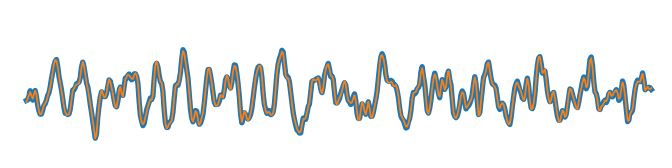 Figure: Randomly chosen original waveform (blue, thick line) with the adversarial waveform (orange, thin line) overlaid.
Figure: Randomly chosen original waveform (blue, thick line) with the adversarial waveform (orange, thin line) overlaid.
Data Poisoning And Deep Learning Based Malware
Data poisoning, a class of adversarial attacks where an adversary has the power to change a fraction of training data in order to satisfy certain objectives. For instance, in 2016, Microsoft’s chatbot Tay.ai was transformed into a racist bot by some Twitter users and was shut down shortly after the launch.
In 2018, IBM security researchers introduced a new malware that applies the characteristics of neural networks in order to hide its malicious payload and to target certain specific users. DeepLocker, a proof-of-concept project that shows the damaging power of AI-powered malware for which they believe that such malware might already exist.
Outlook
The adversarial cases are only lab tested till now and no such cases have been found in real life, however, these experiments prove that there are chances of neural networks turning grey. Artificial Intelligence researchers are trying their best to mitigate the future threats of the adversarial attacks against deep learning and neural network algorithms. For instance, GAN (Generative Adversarial Networks), a deep learning technique that can help in solving such issues. RISE, an explainable AI technique that hardens the neural network algorithms against adversarial attacks.


















