Model evaluation plays a crucial role while developing a predictive machine learning model. Building just a predictive model without checking does not count as a fit model but a model which gives maximum accuracy surely does count a good one. For this, you need to check on the metrics and make improvements accordingly until you get your desired accuracy rate. In this article, we jot down 10 important model evaluation techniques that a machine learning enthusiast must know.
1| Chi-Square
The χ2 test is a method which is used to test the hypothesis between two or more groups in order to check the independence between the two variables. It is basically used to analyse the categorical data and evaluate Tests of Independence when using a bivariate table. Some examples of Chi-Square tests are Fisher’s exact test, Binomial test, etc. The formula for calculating a Chi-Square statistic is given as

Where O represents the observed frequency, E represents the expected frequency.
2| Confusion Matrix

The confusion matrix is also known as Error matrix and is represented by a table which describes the performance of a classification model on a set of test data in machine learning. In the above table, Class 1 is depicted as the positive table and Class 2 is depicted as the negative table. It is a two-dimensional matrix where each row represents the instances in predictive class while each column represents the instances in the actual class or you put the values in the other way. Here, TP (True Positive) means the observation is positive and is predicted as positive, FP (False Positive) means observation is positive but is predicted as negative, TN (True Negative) means the observation is negative and is predicted as negative and FN (False Negative) means the observation is negative but it is predicted as positive.
3| Concordant-Discordant Ratio
In a pair of cases when one case is higher on both the variables than the other cases, it is known as a concordant pair. On the other hand, in a pair of cases where one case is higher on one variable than the other case but lower on the other variable, it is known as a discordant pair.
Suppose, there are a pair of observations (Xa, Ya) and (Xb, Yb)
Then, the pair is concordant if Xa>Xb and Ya>Yb or Xa<Xb and Ya<Yb
And the pair is discordant if Xa>Xb and Ya<Yb or Xa<Xb and Ya>Yb.
4| Confidence Interval
Confidence Interval or CI is the range of values which is required to meet a certain confidence level in order to estimate the features of the total population. In the domain of machine learning, Confidence Intervals basically consist of a range of potential values of an unknown population parameter and the factors which are affecting the width of the confidence interval are the confidence level, size as well as variability of the sample.
5| Gini Co-efficient
The Gini coefficient or Gini Index is a popular metric for imbalanced class values. It is a statistical measure of distribution developed by the Italian statistician Corrado Gini in 1912. The coefficient ranges from 0 to 1 where 0 represent perfect equality and 1 represents perfect inequality. Here, if the value of an index is higher, then the data will be more dispersed.
6| Gain and Lift Chart
This method is generally used to evaluate the performance of the classification model in machine learning and is calculated as the ratio between the results obtained with and without the model. Here, the gain is defined as the ratio of the cumulative number of targets to the total number of targets in the entire dataset and lift is defined as for how many times the model is better than the random choice of cases.
7| Kolmogorov-Smirnov Chart
This non-parametric statistical test measures the performance of classification models where it is defined as the measure of the degree of separation between the positive and negative distributions. The KS test is generally used to compare the equality of a single sample with another.
8| Predictive Power
Predictive Power is a synthetic metric which satisfies interesting properties like it is always been 0 and 1 where 0 represents that the feature subset has no predictive power and 1 represents that the feature subset has maximum predictive power.and is used to select a good subset of features in any machine learning project.
9| AUC-ROC Curve
ROC or Receiver Operating Characteristics Curve is one of the most popular evaluation metrics for checking the performance of a classification model. The curve plots two parameters, True Positive Rate (TPR) and False Positive Rate (FPR). Area Under ROC curve is basically used as a measure of the quality of a classification model. Hence, the AUC-ROC curve is the performance measurement for the classification problem at various threshold settings.
The True Positive Rate or Recall is defined as

The False Positive Rate is defined as

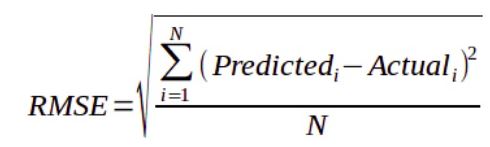
10| Root Mean Square Error
Root Mean Squared Erro or RMSE is defined as the measure of the differences between the values predicted by a model and the values actually observed. It is basically the square root of MSE, Mean Squared Error which is the average of the squared error used as the loss function for least squares regression.
Specifically, the RMSE is defined as